七、幸福的烦恼
还没睡到 3 小时,就被 D 神的电话叫醒:矿池挂了……两人一通排查,认定是使用人数太多导致了内存溢出。不用多说,既然内存不足,就升级机器吧。当初我们选择 DigitalOcean 就是因为它支持快速升级,万一配置不够,点点鼠标,几秒钟就可以升级到更高的配置。重新打开矿池,一切指标都正常,不过我也已经进入了兴奋状态,睡不着了。
我们一边庆幸狗池选在周六发布,这样周日不管出现什么事情都可以及时修复。另一方面也在考虑,有没有什么方法可以及时找出异常,最好在矿池挂掉之前就能发现苗头,及时解决问题。这时,沉默已久的M神突然出现,秒杀了这个需求。M 神有着丰富的运维经验,他手上的服务器多得需要用两位字母加两位数字编号来命名。M 神为几台矿池服务器安装配置了 Munin,这是一个可以在 Web 端一目了然看到 CPU、内存、硬盘、网络等重要系统指标的监视工具。这款工具还可以方便地配置告警条件,比如硬盘快满的时候会提醒我们。这给我们之后及时发现“幸福的烦恼”提供了大量的便利。
分钱 Bug

矿工账单页面插图
看着 X 神画的 gopher 开心分钱的图,心情也是非常的舒畅,但在矿池发布的第二天下午,我们的心情却是非常紧张的。凌晨我们已经见识到了狗池在连续出两个块的时候分钱会有问题,现在随着用户越来越多,出块也越来越快,这个 bug 就发生地更频繁了。这还好,一开始多分了钱,后面就少分点,还是可以慢慢纠正回来的,但是另一个 bug 就更要命了:我们发现,当两个用户同时出块的时候,比特币钱包会告诉我这两个块都成功了……这下就麻烦了,我们以为发出去的钱,其实并没有发出去,后面算的钱就全都错了。一旦有人发现收到的金额不对,就会怀疑狗池在黑他们的钱,这可了得,口碑坏了就什么都没了。
保证分钱的正确性是狗池的首要目标,我们这帮技术宅什么都没,只能靠着目前看来还不错的口碑让狗池继续壮大。第一个 bug 经过 R 神周日加班终于搞定了;第二个 bug 在我看来是比特币钱包留下的坑,既然钱包里不加锁,只能在矿池里加了,结果我加了一堆锁,总算是把这个问题绕过去了,这时的代码已经丑得我不想再改了……几天后,D 神提出了一个完美的无锁方案,彻底解决了这个问题,当然这是后话了。
新版上线
上线一天,狗池的代码还充满了 bug,修修补补免不了要重新发布新版本。作为一个网络服务,发布新版本有着与生俱来的优势:只要在服务器上更新一下就可以了。但是作为一个矿池,上线新版本却又不像网站更新这么容易。首先,我们得保证分钱不能错,share 数据都存在内存里,需要及时备份到硬盘,已经分配的钱需要确认写到数据库里了。其次,重启时间要尽可能快,时间就是金钱,停 1 分钟可能会少赚几毛钱,但是如果停了 10 分钟,可能有些矿工就会跑去别的矿池了,所以这里一定要争分夺秒。
我们最终采用了一种低成本的土办法来上线新版矿池。首先 touch exitpool 发出退出指令,当矿池发现存在“exitpool”这个文件时,就会开始备份各种数据。与此同时,我们人肉观察什么时候矿池结束运行,一旦发现停了,就马上运行新版。新版跑起来之后就要观察指标,万一指标异常,要马上回滚运行之前的版本。回滚命令和运行新版的命令在操作之前都会提前写好,到时候只要直接粘贴就可以了。其实这套方案可以用更自动化的脚本来完成,不过起初我们担心会出错,就在人工监视下一步步执行,后来 bug 少了,矿池也很少更新了,一直没人去写这个脚本,所以直到最后,我们还是这么纯手工地重启矿池。
“DDoS”
那是一个风和日丽的周一下午,狗池经过昨天的调教,已经稳定运行了大半天了。开完了组会,我回到电脑前,看到群里已经有了 N 条未读消息,就冒了个泡“长求总”,紧接着群里就开始刷屏“报告包工头,我们被 DDoS 了”。
其实对于 DDoS,我们早有耳闻,论坛上经常看人提到说某某矿池今天被人 DDoS 了,也有一些矿池主打就是抗 DDoS,用着省心。在做矿池的时候我们也考虑过防 DDoS,不过想着这怎么也得两个月之后才需要考虑吧,怎么这不到两天就……
说回这次 DDoS,其实我们之前都没见过,为什么这么快就认定这是被攻击了呢?回想起下午 1 点多的时候,矿池在线的矿工还只有 1000 人,没想到在之后短短的一小时里,矿工数猛增了 10000 多人,直接导致 CPU 满了。奇怪的是,虽然矿工数多了十倍,但是每分钟 share 数却不见怎么增加。D 神查看日志发现,新进矿池的这 10000 多个“矿工”行为非常异常,一方面大量反复重连,另一方面又几乎不参与计算,因此认定这绝对是被攻击了。
虽说 DDoS 是分布式攻击,但是经过统计发现,这次攻击的 IP 比较集中,D 神、R 神、S 神经过讨论决定,先封杀连接数最多的 100 个
IP。当然,封杀 IP 这么高大上的功能,是不会存在于我们这么快糙猛做出来的矿池里了。好在 Linux 下,可以简单地配置 iptables 直接封杀来自某些 IP 的所有连接。就这样,经过 D 神的一番操作,矿工数降到了 7000。攻击者似乎也意识到了 D
神的封杀,放慢了攻击脚步。此时是下午 4 点,距离发现攻击刚过一小时。
但是这种手工封杀的方式毕竟不是长久之策,最好矿池就有识别恶意连接的功能,直接封杀那批伪矿工。于是我开始仔细分析这些伪矿工的行为。又一番统计之后,我惊奇地发现,那些伪矿工其实也在计算,只不过计算性能非常非常的低。之前见到的矿工,大多是职业矿工,他们用 8 核或是 32 核的服务器来挖矿,也有少量矿工可能是用自己的双核、四核电脑在挖。但这批新矿工,不仅在用单核挖矿,而且挖矿效率低的惊人,基本只有普通单核的四分之一……
那么问题来了,我们要怎么对待这些低效的矿工呢?封杀似乎不一定合理,说不定人家真的就是拿着大量的烂机器,想好好挖矿呢……而且对于我们矿池来说,再弱的矿工也是能给我们带来收益的,我们更应该好好对待他们啊。
既然暂时选择了要好好对待每一个矿工,那只能在自己身上想办法解决问题了。现在的瓶颈在 CPU 上,那么就只有两条出路了,要不优化程序,要不升级机器。回想起昨天才刚升级了机器,现在就要升级了,这还没怎么赚钱,成本就越来越高了,会不会倒闭啊……
我们还是先优化一些已知的问题吧。比如之前为了调试,打印了大量日志,现在是时候砍掉大部分了。经过一番简单地优化,上线一看,确实 CPU 使用率下降了,但是下降地非常微弱(图中箭头处)。
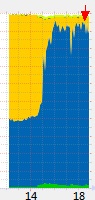
服务器 CPU 使用率变化曲线图(可以看到 CPU 占用在 2 点多开始突然上升)
实际上最方便的找瓶颈的方法是使用性能分析工具。Go 语言也有(pprof),但是似乎不太给力,我们在线上环境测试了一次,分析报告等了一小时还没出来。但是如果线下测试,由于计算量太小,又找不到瓶颈在哪。所以最后还是只能回到人肉分析。
于是我们又一个个模块地分析,在分析到 share 验证模块的时候,我突然想起 H 神写完这个模块的时候提了一句,“每次计算需要 70ms”。现在的 share 数量大约是每分钟 2000 个,也就是说,每秒的计算量是 0.07*2000/60 = 2.3 CPU 秒,一秒钟有两秒多的计算需求,这已经超出了双核 CPU 的极限。看来瓶颈就是在这了,但是这部分计算是必不可少的,而且验证 share 的算法也是非常成熟的,我们也不可能一时半会把它优化下来。哎,还是花钱求平安吧,继续升级服务器。
晚上 8 点,在大家十万个不情愿之下,终于还是把机器升级到了四核,CPU 安静地飘在 75% 的位置上,连接数居然到了接近 2 万;挖矿速度也有了巨大的提升,矿池的算力已经接近数据币全网算力的 50%。看起来之前矿池在双核机器上跑是被严重地压抑了性能。
矿池终于回到了正常状态,可以暂时歇一口气了。接下来的主要任务是优化程序的性能,避免成本一直上涨。但是在此之前,我们还是很想八卦一下这接近两万台机器,到底是谁的。可以肯定的是,这些机器挖到的矿都是给同一个钱包的,说明这些机器都是一个人的。但是谁会有这么多机器呢?我们想来想去觉得只有黑客手中的肉鸡,才会有这么大的规模。但是从 IP 分布来看,这些机器都集中在几个城市,网段也很接近,像是几个网吧的。不过网吧一般都有还原卡,不太容易中木马……真是越想越绕,不知道到底是何方神圣。还是随他去吧,能让我们赚钱就行。