这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享。其中必然有局限性,欢迎各种交流,随便拍。
Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果。关于这个原因,引一条我比较赞同的微博。
2013年3月4日 14:46
第一句就先不用管了,毕竟今年的 ACL 已经被灌了好多 Deep Learning 的论文了。第二句我很认同,不过我也有信心以后一定有人能挖掘出语言这种高层次抽象中的本质。不论最后这种方法是不是 Deep Learning,就目前而言,Deep Learning 在 NLP 领域中的研究已经将高深莫测的人类语言撕开了一层神秘的面纱。
我觉得其中最有趣也是最基本的,就是“词向量”了。
将词用“词向量”的方式表示可谓是将 Deep Learning 算法引入 NLP 领域的一个核心技术。大多数宣称用了 Deep Learning 的论文,其中往往也用了词向量。
0. 词向量是什么
1. 词向量的来历
2. 词向量的训练
2.0 语言模型简介
2.1 Bengio 的经典之作
2.2 C&W 的 SENNA
2.3 M&H 的 HLBL
2.4 Mikolov 的 RNNLM
2.5 Huang 的语义强化
2.999 总结
3. 词向量的评价
3.1 提升现有系统
3.2 语言学评价
参考文献
0. 词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个栗子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
当然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation(不知道这个应该怎么翻译,因为还存在一种叫“Distributional Representation”的表示方法,又是另一个不同的概念)表示的一种低维实数向量。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的,后文会提到目前计算出这种向量的主流方法。
(个人认为)Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
1. 词向量的来历
Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的。虽然这篇文章没有说要将词做 Distributed representation,(甚至我很无厘头地猜想那篇文章是为了给他刚提出的 BP 网络打广告,)但至少这种先进的思想在那个时候就在人们的心中埋下了火种,到 2000 年之后开始逐渐被人重视。
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量”。真的只能叫“俗称”,算不上翻译。半年前我本想翻译的,但是硬是想不出 Embedding 应该怎么翻译的,后来就这么叫习惯了-_-||| 如果有好的翻译欢迎提出。(更新:@南大周志华 在这篇微博中给了一个合适的翻译:词嵌入)Embedding 一词的意义可以参考维基百科的相应页面(链接)。后文提到的所有“词向量”都是指用 Distributed Representation 表示的词向量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
同时如上一节提到的,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
2. 词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。
这也比较容易理解,要从一段无标注的自然文本中学习出一些东西,无非就是统计出词频、词的共现、词的搭配之类的信息。而要从自然文本中统计并建立一个语言模型,无疑是要求最为精确的一个任务(也不排除以后有人创造出更好更有用的方法)。既然构建语言模型这一任务要求这么高,其中必然也需要对语言进行更精细的统计和分析,同时也会需要更好的模型,更大的数据来支撑。目前最好的词向量都来自于此,也就不难理解了。
这里介绍的工作均为从大量未标注的普通文本数据中无监督地学习出词向量(语言模型本来就是基于这个想法而来的),可以猜测,如果用上了有标注的语料,训练词向量的方法肯定会更多。不过视目前的语料规模,还是使用未标注语料的方法靠谱一些。
词向量的训练最经典的有 3 个工作,C&W 2008、M&H 2008、Mikolov 2010。当然在说这些工作之前,不得不介绍一下这一系列中 Bengio 的经典之作。
2.0 语言模型简介
插段广告,简单介绍一下语言模型,知道的可以无视这节。
语言模型其实就是看一句话是不是正常人说出来的。这玩意很有用,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结果。在 NLP 的其它任务里也都能用到。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率 $P(w_1, w_2, …, w_t)$。$w_1$ 到 $w_t$ 依次表示这句话中的各个词。有个很简单的推论是:
$P(w_1, w_2, …, w_t) = P(w_1) \times P(w_2 | w_1) \times P(w_3 | w_1, w_2) \times … \times P(w_t | w_1, w_2, …, w_{t-1}) $
常用的语言模型都是在近似地求 $P(w_t | w_1, w_2, …, w_{t-1})$。比如 n-gram 模型就是用 $P(w_t | w_{t-n+1}, …, w_{t-1})$ 近似表示前者。
顺便提一句,由于后面要介绍的每篇论文使用的符号差异太大,本博文里尝试统一使用 Bengio 2003 的符号系统(略做简化),以便在各方法之间做对比和分析。
2.1 Bengio 的经典之作
用神经网络训练语言模型的思想最早由百度 IDL 的徐伟于 2000 提出。(感谢 @余凯_西二旗民工 博士指出。)其论文《Can Artificial Neural Networks Learn Language Models?》提出一种用神经网络构建二元语言模型(即 $P(w_t|w_{t-1})$)的方法。文中的基本思路与后续的语言模型的差别已经不大了。
训练语言模型的最经典之作,要数 Bengio 等人在 2001 年发表在 NIPS 上的文章《A Neural Probabilistic Language Model》。当然现在看的话,肯定是要看他在 2003 年投到 JMLR 上的同名论文了。
Bengio 用了一个三层的神经网络来构建语言模型,同样也是 n-gram 模型。如图1。
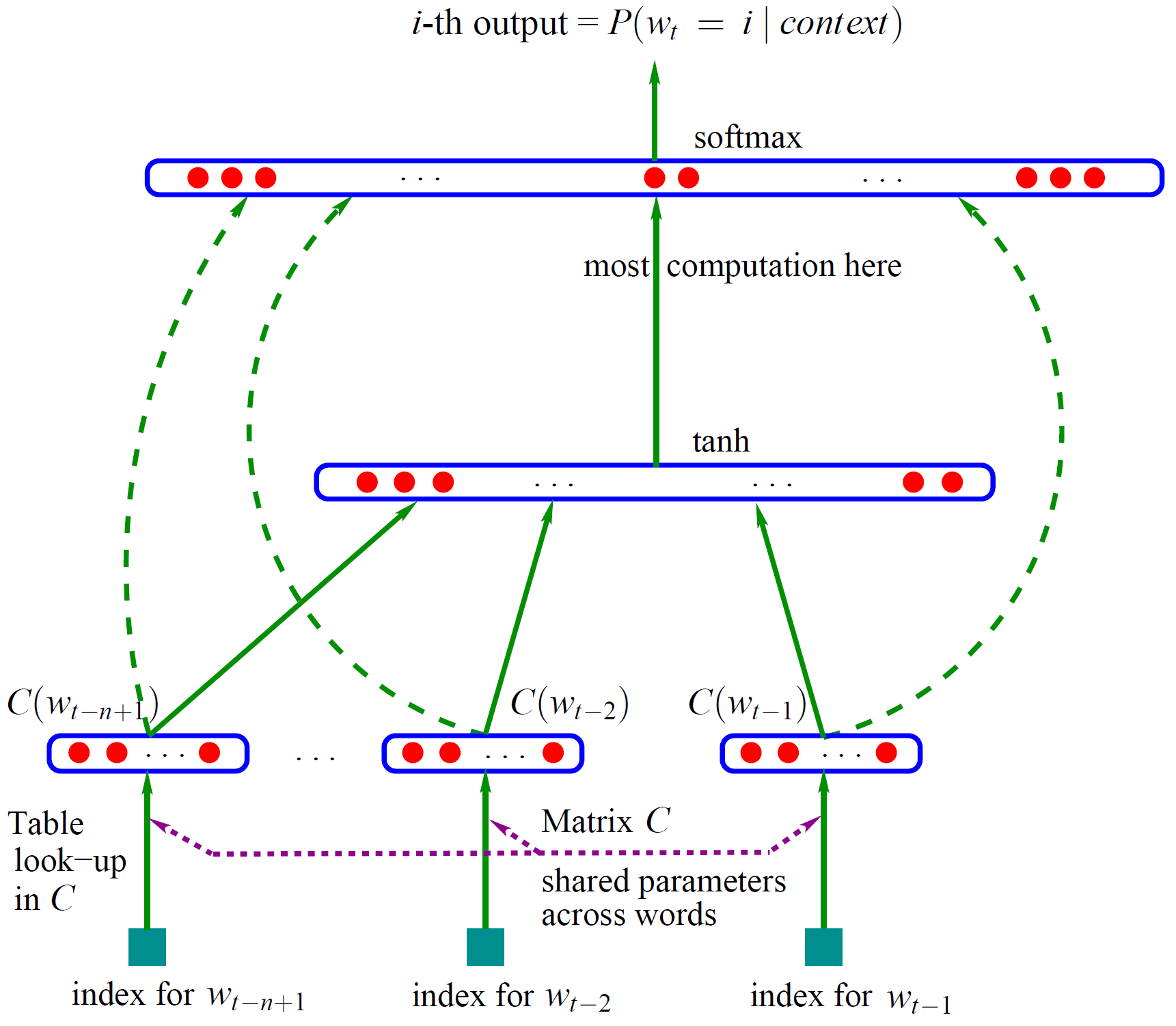
图1(点击查看大图)
图中最下方的 $w_{t-n+1}, …, w_{t-2}, w_{t-1}$ 就是前 $n-1$ 个词。现在需要根据这已知的 $n-1$ 个词预测下一个词 $w_t$。$C(w)$ 表示词 $w$ 所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 $C$(一个 $|V| \times m$ 的矩阵)中。其中 $|V|$ 表示词表的大小(语料中的总词数),$m$ 表示词向量的维度。$w$ 到 $C(w)$ 的转化就是从矩阵中取出一行。
网络的第一层(输入层)是将 $C(w_{t-n+1}), …, C(w_{t-2}), C(w_{t-1})$ 这 $n-1$ 个向量首尾相接拼起来,形成一个 $(n-1)m$ 维的向量,下面记为 $x$。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用 $d+Hx$ 计算得到。$d$ 是一个偏置项。在此之后,使用 $\tanh$ 作为激活函数。
网络的第三层(输出层)一共有 $|V|$ 个节点,每个节点 $y_i$ 表示 下一个词为 $i$ 的未归一化 log 概率。最后使用 softmax 激活函数将输出值 $y$ 归一化成概率。最终,$y$ 的计算公式为:
式子中的 $U$(一个 $|V|\times h$ 的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在 $U$ 和隐藏层的矩阵乘法中。后文的提到的 3 个工作,都有对这一环节的简化,提升计算的速度。
式子中还有一个矩阵 $W$($|V|\times(n-1)m$),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经网络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将 $W$ 置为 0 就可以了。在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层 $x$ 也是参数(存在 $C$ 中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
这样得到的语言模型自带平滑,无需传统 n-gram 模型中那些复杂的平滑算法。Bengio 在 APNews 数据集上做的对比实验也表明他的模型效果比精心设计平滑算法的普通 n-gram 算法要好 10% 到 20%。
在结束介绍 Bengio 大牛的经典作品之前再插一段八卦。在其 JMLR 论文中的未来工作一段,他提了一个能量函数,把输入向量和输出向量统一考虑,并以最小化能量函数为目标进行优化。后来 M&H 工作就是以此为基础展开的。
他提到一词多义有待解决,9 年之后 Huang 提出了一种解决方案。他还在论文中随口(不是在 Future Work 中写的)提到:可以使用一些方法降低参数个数,比如用循环神经网络。后来 Mikolov 就顺着这个方向发表了一大堆论文,直到博士毕业。
大牛就是大牛。
2.2 C&W 的 SENNA
Ronan Collobert 和 Jason Weston 在 2008 年的 ICML 上发表的《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》里面首次介绍了他们提出的词向量的计算方法。和上一篇牛文类似,如果现在要看的话,应该去看他们在 2011 年投到 JMLR 上的论文《Natural Language Processing (Almost) from Scratch》。文中总结了他们的多项工作,非常有系统性。这篇 JMLR 的论文题目也很霸气啊:从头开始搞 NLP。他们还把论文所写的系统开源了,叫做 SENNA(主页链接),3500 多行纯 C 代码也是写得非常清晰。我就是靠着这份代码才慢慢看懂这篇论文的。可惜的是,代码只有测试部分,没有训练部分。
实际上 C&W 这篇论文主要目的并不是在于生成一份好的词向量,甚至不想训练语言模型,而是要用这份词向量去完成 NLP 里面的各种任务,比如词性标注、命名实体识别、短语识别、语义角色标注等等。
由于目的的不同,C&W 的词向量训练方法在我看来也是最特别的。他们没有去近似地求 $P(w_t | w_1, w_2, …, w_{t-1})$,而是直接去尝试近似 $P(w_1, w_2, …, w_t)$。在实际操作中,他们并没有去求一个字符串的概率,而是求窗口连续 $n$ 个词的打分 $f(w_{t-n+1}, …, w_{t-1}, w_t)$。打分 $f$ 越高的说明这句话越是正常的话;打分低的说明这句话不是太合理;如果是随机把几个词堆积在一起,那肯定是负分(差评)。打分只有相对高低之分,并没有概率的特性。
有了这个对 $f$ 的假设,C&W 就直接使用 pair-wise 的方法训练词向量。具体的来说,就是最小化下面的目标函数。
$\mathfrak{X}$ 为训练集中的所有连续的 $n$ 元短语,$\mathfrak{D}$ 是整个字典。第一个求和枚举了训练语料中的所有的 $n$ 元短语,作为正样本。第二个对字典的枚举是构建负样本。$x^{(w)}$ 是将短语 $x$ 的最中间的那个词,替换成 $w$。在大多数情况下,在一个正常短语的基础上随便找个词替换掉中间的词,最后得到的短语肯定不是正确的短语,所以这样构造的负样本是非常可用的(多数情况下确实是负样本,极少数情况下把正常短语当作负样本也不影响大局)。同时,由于负样本仅仅是修改了正样本中的一个词,也不会让分类面距离负样本太远而影响分类效果。再回顾这个式子,$x$ 是正样本,$x^{(w)}$ 是负样本,$f(x)$ 是对正样本的打分,$f(x^{(w)})$ 是对负样本的打分。最后希望正样本的打分要比负样本的打分至少高 1 分。
$f$ 函数的结构和 Bengio 2003 中提到的网络结构基本一致。同样是把窗口中的 $n$ 个词对应的词向量串成一个长的向量,同样是经过一层网络(乘一个矩阵)得到隐藏层。不同之处在于 C&W 的输出层只有一个节点,表示得分,而不像 Bengio 那样的有 $|V|$ 个节点。这么做可以大大降低计算复杂度,当然有这种简化还是因为 C&W 并不想做一个真正的语言模型,只是借用语言模型的思想辅助他完成 NLP 的其它任务。(其实 C&W 的方法与 Bengio 的方法还有一个区别,他们为了程序的效率用 $\textrm{HardTanh}$ 代替 $\tanh$ 激活函数。)
他们在实验中取窗口大小 $n=11$,字典大小 $|V|=130000$,在维基百科英文语料和路透社语料中一共训练了 7 周,终于得到了这份伟大的词向量。
如前面所说 C&W 训练词向量的动机与其他人不同,因此他公布的词向量与其它词向量相比主要有两个区别:
1.他的词表中只有小写单词。也就是说他把大写开头的单词和小写单词当作同一个词处理。其它的词向量都是把他们当作不同的词处理的。
2.他公布的词向量并不直接是上述公式的优化结果,而是在此基础上进一步跑了词性标注、命名实体识别等等一系列任务的 Multi-Task Learning 之后,二次优化得到的。也可以理解为是半监督学习得到的,而非其他方法中纯无监督学习得到的。
不过好在 Turian 在 2010 年对 C&W 和 M&H 向量做对比时,重新训练了一份词向量放到了网上,那份就没上面的两个“问题”(确切的说应该是差别),也可以用的更放心。后面会详细介绍 Turian 的工作。
关于这篇论文其实还是有些东西可以吐槽的,不过训练词向量这一块没有,是论文其他部分的。把吐槽机会留给下一篇博文了。
2.3 M&H 的 HLBL
Andriy Mnih 和 Geoffrey Hinton 在 2007 年和 2008 年各发表了一篇关于训练语言模型和词向量的文章。2007 年发表在 ICML 上的《Three new graphical models for statistical language modelling》表明了 Hinton 将 Deep Learning 战场扩展到 NLP 领域的决心。2008 年发表在 NIPS 上的《A scalable hierarchical distributed language model》则提出了一种层级的思想替换了 Bengio 2003 方法中最后隐藏层到输出层最花时间的矩阵乘法,在保证效果的基础上,同时也提升了速度。下面简单介绍一下这两篇文章。
Hinton 在 2006 年提出 Deep Learning 的概念之后,很快就来 NLP 最基础的任务上试了一把。果然,有效。M&H 在 ICML 2007 上发表的这篇文章提出了“Log-Bilinear”语言模型。文章标题中可以看出他们其实一共提了 3 个模型。从最基本的 RBM 出发,一点点修改能量函数,最后得到了“Log-Bilinear”模型。
模型如果用神经网络的形式写出来,是这个样子:
这里的两个式子可以合写成一个 $y_j = \sum\limits_{i=1}^{n-1}{C(w_j)^T H_i C(w_i)}$。$C(w)$ 是词 $w$ 对应的词向量,形如 $x^T M y$ 的模型叫做 Bilinear 模型,也就是 M&H 方法名字的来历了。
为了更好地理解模型的含义,还是来看这两个拆解的式子。$h$ 在这里表示隐藏层,这里的隐藏层比前面的所有模型都更厉害,直接有语义信息。首先从第二个式子中隐藏层能和词向量直接做内积可以看出,隐藏层的维度和词向量的维度是一致的(都是 $m$ 维)。$H_i$ 就是一个 $m \times m$ 的矩阵,该矩阵可以理解为第 $i$ 个词经过 $H_i$ 这种变换之后,对第 $t$ 个词产生的贡献。因此这里的隐藏层是对前 $t-1$ 个词的总结,也就是说隐藏层 $h$ 是对下一个词的一种预测。
再看看第二个式子,预测下一个词为 $w_j$ 的 log 概率是 $y_j$,它直接就是 $C(w_j)$ 和 $h$ 的内积。内积基本上就可以反应相似度,如果各词向量的模基本一致的话,内积的大小能直接反应两个向量的 cos 夹角的大小。这里使用预测词向量 $h$ 和各个已知词的词向量的相似度作为 log 概率,将词向量的作用发挥到了极致。这也是我觉得这次介绍的模型中最漂亮的一个。
这种“Log-Bilinear”模型看起来每个词需要使用上文所有的词作为输入,于是语料中最长的句子有多长,就会有多少个 $H$ 矩阵。这显然是过于理想化了。最后在实现模型时,还是迫于现实的压力,用了类似 n-gram 的近似,只考虑了上文的 3 到 5 个词作为输入来预测下一个词。
M&H 的思路如前面提到,是 Bengio 2003 提出的。经过大牛的实现,效果确实不错。虽然复杂度没有数量级上的降低,但是由于是纯线性模型,没有激活函数(当然在做语言模型的时候,最后还是对 $y_j$ 跑了一个 softmax),因此实际的训练和预测速度都会有很大的提升。同时隐藏层到输出层的变量直接用了词向量,这也就几乎少了一半的变量,使得模型更为简洁。最后论文中 M&H 用了和 Bengio 2003 完全一样的数据集做实验,效果有了一定的提升。
2008 年 NIPS 的这篇论文,介绍的是“hierarchical log-bilinear”模型,很多论文中都把它称作简称“HLBL”。和前作相比,该方法使用了一个层级的结构做最后的预测。可以简单地设想一下把网络的最后一层变成一颗平衡二叉树,二叉树的每个非叶节点用于给预测向量分类,最后到叶节点就可以确定下一个词是哪个了。这在复杂度上有显著的提升,以前是对 $|V|$ 个词一一做比较,最后找出最相似的,现在只需要做 $\log_2(|V|)$ 次判断即可。
这种层级的思想最初可见于 Frederic Morin 和 Yoshua Bengio 于 2005 年发表的论文《Hierarchical probabilistic neural network language model》中。但是这篇论文使用 WordNet 中的 IS-A 关系,转化为二叉树用于分类预测。实验结果发现速度提升了,效果变差了。
有了前车之鉴,M&H 就希望能从语料中自动学习出一棵树,并能达到比人工构建更好的效果。M&H 使用一种 bootstrapping 的方法来构建这棵树。从随机的树开始,根据分类结果不断调整和迭代。最后得到的是一棵平衡二叉树,并且同一个词的预测可能处于多个不同的叶节点。这种用多个叶节点表示一个词的方法,可以提升下一个词是多义词时候的效果。M&H 做的还不够彻底,后面 Huang 的工作直接对每个词学习出多个词向量,能更好地处理多义词。
2.4 Mikolov 的 RNNLM
前文说到,Bengio 2003 论文里提了一句,可以使用一些方法降低参数个数,比如用循环神经网络。Mikolov 就抓住了这个坑,从此与循环神经网络结下了不解之缘。他最早用循环神经网络做语言模型是在 INTERSPEECH 2010 上发表的《Recurrent neural network based language model》里。Recurrent neural network 是循环神经网络,简称 RNN,还有个 Recursive neural networks 是递归神经网络(Richard Socher 借此发了一大堆论文),也简称 RNN。看到的时候需要注意区分一下。不过到目前为止,RNNLM 只表示循环神经网络做的语言模型,还没有歧义。
在之后的几年中,Mikolov 在一直在RNNLM 上做各种改进,有速度上的,也有准确率上的。现在想了解 RNNLM,看他的博士论文《Statistical Language Models based on Neural Networks》肯定是最好的选择。
循环神经网络与前面各方法中用到的前馈网络在结构上有比较大的差别,但是原理还是一样的。网络结构大致如图2。
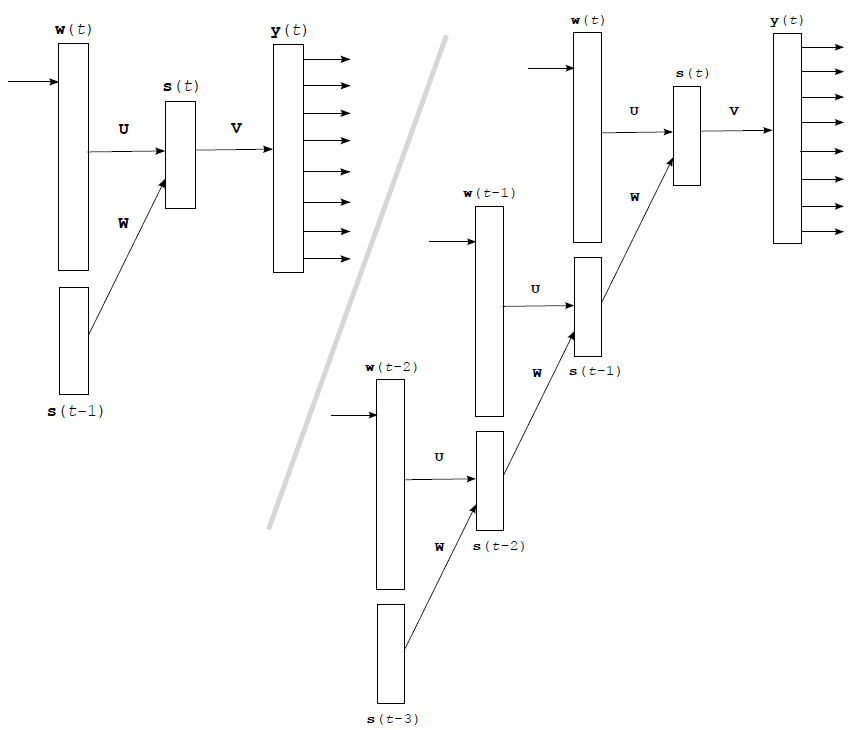
图2(点击查看大图)
左边是网络的抽象结构,由于循环神经网络多用在时序序列上,因此里面的输入层、隐藏层和输出层都带上了“(t)”。$w(t)$ 是句子中第 $t$ 个词的 One-hot representation 的向量,也就是说 $w$ 是一个非常长的向量,里面只有一个元素是 1。而下面的 $s(t-1)$ 向量就是上一个隐藏层。最后隐藏层计算公式为:
从右图可以看出循环神经网络是如何展开的。每来一个新词,就和上一个隐藏层联合计算出下一个隐藏层,隐藏层反复利用,一直保留着最新的状态。各隐藏层通过一层传统的前馈网络得到输出值。
$w(t)$ 是一个词的 One-hot representation,那么 $U w(t)$ 也就相当于从矩阵 $U$ 中选出了一列,这一列就是该词对应的词向量。
循环神经网络的最大优势在于,可以真正充分地利用所有上文信息来预测下一个词,而不像前面的其它工作那样,只能开一个 n 个词的窗口,只用前 n 个词来预测下一个词。从形式上看,这是一个非常“终极”的模型,毕竟语言模型里能用到的信息,他全用上了。可惜的是,循环神经网络形式上非常好看,使用起来却非常难优化,如果优化的不好,长距离的信息就会丢失,甚至还无法达到开窗口看前若干个词的效果。Mikolov 在 RNNLM 里面只使用了最朴素的 BPTT 优化算法,就已经比 n-gram 中的 state of the art 方法有更好的效果,这非常令人欣慰。如果用上了更强的优化算法,最后效果肯定还能提升很多。
对于最后隐藏层到输出层的巨大计算量,Mikolov 使用了一种分组的方法:根据词频将 $|V|$ 个词分成 $\sqrt{|V|}$ 组,先通过 $\sqrt{|V|}$ 次判断,看下一个词属于哪个组,再通过若干次判断,找出其属于组内的哪个元素。最后均摊复杂度约为 $o(\sqrt{|V|})$,略差于 M&H 的 $o(\log(|V|))$,但是其浅层结构某种程度上可以减少误差传递,也不失为一种良策。
Mikolov 的 RNNLM 也是开源的(网址)。非常算法风格的代码,几乎所有功能都在一个文件里,工程也很好编译。比较好的是,RNNLM 可以完美支持中文,如果语料存成 UTF-8 格式,就可以直接用了。
最后吐槽一句,我觉得他在隐藏层用 sigmoid 作为激活函数不够漂亮。因为隐藏层要和输入词联合计算得到下一个隐藏层,如果当前隐藏层的值全是正的,那么输入词对应的参数就会略微偏负,也就是说最后得到的词向量的均值不在 0 附近。总感觉不好看。当然,从实验效果看,是我太强迫症了。
2.5 Huang 的语义强化
与前几位大牛的工作不同,Eric H. Huang 的工作是在 C&W 的基础上改进而成的,并非自成一派从头做起。他这篇发表在 ACL 2012 上的《Improving Word Representations via Global Context and Multiple Word Prototypes》试图通过对模型的改进,使得词向量富含更丰富的语义信息。他在文中提出了两个主要创新来完成这一目标:(其实从论文标题就能看出来)第一个创新是使用全文信息辅助已有的局部信息,第二个创新是使用多个词向量来表示多义词。下面逐一介绍。
Huang 认为 C&W 的工作只利用了“局部上下文(Local Context)”。C&W 在训练词向量的时候,只使用了上下文各 5 个词,算上自己总共有 11 个词的信息,这些局部的信息还不能充分挖掘出中间词的语义信息。Huang 直接使用 C&W 的网络结构计算出一个得分,作为“局部得分”。
然后 Huang 提出了一个“全局信息”,这有点类似传统的词袋子模型。词袋子模型是把文章中所有词的 One-hot Representation 加起来,形成一个向量(就像把词全都扔进一个袋子里),用来表示文章。Huang 的全局模型是将文章中所有词的词向量求个加权平均(权重是词的 idf),作为文章的语义。他把文章的语义向量和当前词的词向量拼接起来,形成一个两倍长度的向量作为输入,之后还是用 C&W 的网络结构算出一个打分。
有了 C&W 方法的得到的“局部得分”,再加上在 C&W 方法基础上改造得到的“全局得分”,Huang 直接把两个得分相加,作为最终得分。最终得分使用 C&W 提出的 pair-wise 目标函数来优化。
加了这个全局信息有什么用处呢?Huang 在实验中发现,他的模型能更好地捕捉词的语义信息。比如 C&W 的模型中,与 markets 最相近的词为 firms、industries;而 Huang 的模型得到的结果是 market、firms。很明显,C&W 的方法由于只考虑了临近词的信息,最后的结果是词法特征最相近的词排在了前面(都是复数形式)。不过我觉得这个可能是英语才有的现象,中文没有词形变化,如果在中文中做同样的实验还不知道会有什么效果。
Huang 论文的第二个贡献是将多义词用多个词向量来表示。Bengio 2003 在最后提过这是一个重要的问题,不过当时他还在想办法解决,现在 Huang 给出了一种思路。
将每个词的上下文各 5 个词拿出来,对这 10 个词的词向量做加权平均(同样使用 idf 作为权重)。对所有得到的上下文向量做 k-means 聚类,根据聚类结果给每个词打上标签(不同类中的同一个词,当作不同的词处理),最后重新训练词向量。
当然这个实验的效果也是很不错的,最后 star 的某一个表示最接近的词是 movie、film;另一个表示最接近的词是 galaxy、planet。
这篇文章还做了一些对比实验,在下一章评价里细讲。
2.999 总结
//博主道:本节承上启下,不知道应该放在第 2 章还是第 3 章,便将小节号写为 2.999。
讲完了大牛们的各种方法,自己也忍不住来总结一把。当然,为了方便对比,我先列举一下上面提到的各个系统的现有资源,见下表。对应的论文不在表中列出,可参见最后的参考文献。
| 名称 | 训练语料及规模 | 词向量 | 特点 | 资源 |
|---|---|---|---|---|
| C&W | English Wikipedia + Reuters RCV1 共 631M + 221M 词 | 130000 词 50 维 | 不区分大小写; 经过有监督修正; 训练了 7 周 | 测试代码、 词向量 [链接] |
| C&W - Turian | Reuters RCV1 63M 词 | 268810 词 25、50、 100、200 维 | 区分大小写; 训练了若干周 | 训练代码、 词向量 [链接] |
| M&H - Turian | Reuters RCV1 | 246122 词 50、100 维 | 区分大小写; 用GPU训练了7天 | 词向量 [链接] |
| Mikolov | Broadcast news | 82390 词 80、640、 1600 维 | 不区分大小写; 训练了若干天 | 训练、测试代码、 词向量 [链接] |
| Huang 2012 | English Wikipedia | 100232 词 50 维 | 不区分大小写; 最高频的6000词, 每词有10种表示 | 训练、测试代码、 语料及词向量 [链接] |
Turian 的工作前面只是提了一下,他在做 C&W 向量与 H&M 向量的对比实验时,自己按照论文重新实现了一遍他们的方法,并公布了词向量。后来 C&W 在主页上强调了一下:尽管很多论文把 Turian 实现的结果叫做 C&W 向量,但是与我发布的词向量是不同的,我这个在更大的语料上训练,还花了两个月时间呢!
Turian 公布的 H&M 向量是直接请 Andriy Mnih 在 Turian 做好的语料上运行了一下 HLBL,所以没有代码公布。同时 Turian 自己实现了一份 LBL模型,但是没有公布训练出来的词向量。(这是根据他主页上描述推测的结果,从 Turian 的论文中看,他应该是实现了 HLBL 算法并且算出词向量的。)
RCV1 的词数两篇文章中所写的数据差距较大,还不知道是什么原因。
Holger Schwenk 在词向量和语言模型方面也做了一些工作,看起来大体相似,也没仔细读过他的论文。有兴趣的读者可以直接搜他的论文。
事实上,除了 RNNLM 以外,上面其它所有模型在第一层(输入层到隐藏层)都是等价的,都可以看成一个单层网络。可能形式最为特别的是 M&H 的模型,对前面的每个词单独乘以矩阵 $H_i$,而不是像其它方法那样把词向量串接起来乘以矩阵 $H$。但如果把 $H$ 看成 $H_i$ 的拼接: $[H_1 H_2 … H_t]$,则会有以下等式:
这么看来还是等价的。
所以前面的这么多模型,本质是非常相似的。都是从前若干个词的词向量通过线性变换抽象出一个新的语义(隐藏层),再通过不同的方法来解析这个隐藏层。模型的差别主要就在隐藏层到输出层的语义。Bengio 2003 使用了最朴素的线性变换,直接从隐藏层映射到每个词;C&W 简化了模型(不求语言模型),通过线性变换将隐藏层转换成一个打分;M&H 复用了词向量,进一步强化了语义,并用层级结构加速;Mikolov 则用了分组来加速。
每种方法真正的差别看起来并不大,当然里面的这些创新,也都是有据可循的。下一章就直接来看看不同模型的效果如何。
3. 词向量的评价
词向量的评价大体上可以分成两种方式,第一种是把词向量融入现有系统中,看对系统性能的提升;第二种是直接从语言学的角度对词向量进行分析,如相似度、语义偏移等。
3.1 提升现有系统
词向量的用法最常见的有两种:
1. 直接用于神经网络模型的输入层。如 C&W 的 SENNA 系统中,将训练好的词向量作为输入,用前馈网络和卷积网络完成了词性标注、语义角色标注等一系列任务。再如 Socher 将词向量作为输入,用递归神经网络完成了句法分析、情感分析等多项任务。
2. 作为辅助特征扩充现有模型。如 Turian 将词向量作为额外的特征加入到接近 state of the art 的方法中,进一步提高了命名实体识别和短语识别的效果。
具体的用法理论上会在下一篇博文中细讲。
C&W 的论文中有一些对比实验。实验的结果表明,使用词向量作为初始值替代随机初始值,其效果会有非常显著的提升(如:词性标注准确率从 96.37% 提升到 97.20%;命名实体识别 F 值从 81.47% 提升到 88.67%)。同时使用更大的语料来训练,效果也会有一些提升。
Turian 发表在 ACL 2010 上的实验对比了 C&W 向量与 M&H 向量用作辅助特征时的效果。在短语识别和命名实体识别两个任务中,C&W 向量的效果都有略微的优势。同时他也发现,如果将这两种向量融合起来,会有更好的效果。除了这两种词向量,Turian 还使用 Brown Cluster 作为辅助特征做了对比,效果最好的其实是 Brown Cluster,不过这个已经超出本文的范围了。
3.2 语言学评价
Huang 2012 的论文提出了一些创新,能提升词向量中的语义成分。他也做了一些实验对比了各种词向量的语义特性。实验方法大致就是将词向量的相似度与人工标注的相似度做比较。最后 Huang 的方法语义相似度最好,其次是 C&W 向量,再然后是 Turian 训练的 HLBL 向量与 C&W 向量。这里因为 Turian 训练词向量时使用的数据集(RCV1)与其他的对比实验(Wiki)并不相同,因此并不是非常有可比性。但从这里可以推测一下,可能更大更丰富的语料对于语义的挖掘是有帮助的。
还有一个有意思的分析是 Mikolov 在 2013 年刚刚发表的一项发现。他发现两个词向量之间的关系,可以直接从这两个向量的差里体现出来。向量的差就是数学上的定义,直接逐位相减。比如 $C(\textrm{king})-C(\textrm{queen}) \approx C(\textrm{man})-C(\textrm{woman})$。更强大的是,与 $C(\textrm{king})- C(\textrm{man})+C(\textrm{woman})$ 最接近的向量就是 $C(\textrm{queen})$。
为了分析词向量的这个特点, Mikolov 使用类比(analogy)的方式来评测。如已知 a 之于 b 犹如 c 之于 d。现在给出 a、b、c,看 $C(a)-C(b)+C(c)$ 最接近的词是否是 d。
在文章 Mikolov 对比了词法关系(名词单复数 good-better:rough-rougher、动词第三人称单数、形容词比较级最高级等)和语义关系(clothing-shirt:dish-bowl)。
在词法关系上,RNN 的效果最好,然后是 Turian 实现的 HLBL,最后是 Turian 的 C&W。(RNN-80:19%;RNN-1600:39.6%;HLBL-100:18.7%;C&W-100:5%;-100表示词向量为100维)
在语义关系上,表现最好的还是 RNN,然后是 Turian 的两个向量,差距没刚才的大。(RNN-80:0.211;C&W-100:0.154;HLBL-100:0.146)
但是这个对比实验用的训练语料是不同的,也不能特别说明优劣。
这些实验结果中最容易理解的是:语料越大,词向量就越好。其它的实验由于缺乏严格控制条件进行对比,谈不上哪个更好哪个更差。不过这里的两个语言学分析都非常有意思,尤其是向量之间存在这种线性平移的关系,可能会是词向量发展的一个突破口。
参考文献
Yoshua Bengio, Rejean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of Machine Learning Research (JMLR), 3:1137–1155, 2003. [PDF]
Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu and Pavel Kuksa. Natural Language Processing (Almost) from Scratch. Journal of Machine Learning Research (JMLR), 12:2493-2537, 2011. [PDF]
Andriy Mnih & Geoffrey Hinton. Three new graphical models for statistical language modelling. International Conference on Machine Learning (ICML). 2007. [PDF]
Andriy Mnih & Geoffrey Hinton. A scalable hierarchical distributed language model. The Conference on Neural Information Processing Systems (NIPS) (pp. 1081–1088). 2008. [PDF]
Mikolov Tomáš. Statistical Language Models based on Neural Networks. PhD thesis, Brno University of Technology. 2012. [PDF]
Turian Joseph, Lev Ratinov, and Yoshua Bengio. Word representations: a simple and general method for semi-supervised learning. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL). 2010. [PDF]
Eric Huang, Richard Socher, Christopher Manning and Andrew Ng. Improving word representations via global context and multiple word prototypes. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. 2012. [PDF]
Mikolov, Tomas, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. Proceedings of NAACL-HLT. 2013. [PDF]
断断续续写了这么多,如果有人看加上自己有时间的话,还会有续集《Deep Learning in NLP (二)模型及用法》,也是介绍几篇文章,从模型的层次做一些粗浅的分析。
请问有关于中文的word embedding的研究吗?
我很好奇中文的复合词的word embedded表示是否也有类似 king – queen = man – woman的语言学现象。
中文目前只看到有用词向量的文章,比如做分词任务。还没看到分析语言学现象的文章。
博主不知道能不能提供下中文用词向量来做分词的论文或者资料吗?多谢了
今年CNCCL上至少有两个工作是关于这个的。一个是我们做的,还有一个是张开旭做的(参考 http://weibo.com/1407224844/zFLvrDOMc)。会议要10月开,可能要到时候才会有详情公布。
问问博主,现在有做中文词嵌入这方面工作的吗?我查了一些相关文献,貌似不多。
我也觉得不多。我博士论文里有一章是介绍中文词向量的,可以大概看一下,也可以继续顺着参考文献找一些。
哇,王兄这么早就开始研究这个啦?你是工大计算机学院硕士毕业的吧?我估计是你研究生同学。
博主,怎么那些你给的链接找不到相关的训练代码和训练好的词向量呢?
可能时间太久链接失效了吧。现在用word2vec就行了。
Nice work! 受教了
有深度,有广度,真心佩服博主,顶一个。
写的很好,如果深度学习能广泛用于NLP领域,那将NLP将大大地前进一步
期待 Deep Learning in NLP (二)模型及用法 出现啊,也希望能够多多交流,一起进步
居然没人抢沙发?
言浅意深,很棒的文章!
另外个人不是很理解“循环神经网络”里“循环”的意旨在哪,看起来只是单方向运用了前文的所有信息不断加入隐藏层呀……
期待系列更新!
可以理解为,每个词的信息依次加入隐藏层。这个依次加入就是个循环的过程,因为每次加入的算法都是一样的。
RNN中每次R的参数W和U都是相同的吧
是的
U和W不应该是每次R都会修改吗?要不然learning什么呢?不就是在learn参数吗?为什么会是相同的呢?
整个网络共享一份U和W。
测试的时候,就是一样的。
训练的时候,只能说是共享同一个矩阵,每个样本都会更新一次U和W。同一批参数,值会变。
真的很好,好好学习一下
不错!
topic model的word的主题维德表示,看来也是一种Distributed representation了。不知道哪种在对空间位置的刻画上更加准确一些
Topic Model 这种是叫 Distributional Representation,Turian 的论文里面还特地区分了一下。我实在没法从名字里看出他们的特点。 我觉得topic model着眼于篇章级的统计,文中的方法都集中于上下文的分析,应该各有优劣吧。还没见人仔细对比分析过这两种方案。
感觉topic model主要是为了计算文章的主题分部,而把词看成主题的支撑和表示;word embedding则直接在词维度做成了向量表示。
所有的Topic Model所依赖的都是文章中词与词的共现关系。即便两个词在theme上再相似,如果在当前语料里没有共现的话,也很难学习到一个话题里。至少我是这么理解的
博主,请教个问题,您在文中提到的
“所有训练方法都是在训练语言模型的同时,顺便得到词向量的。”
在这个基础上理解C&W的结构有些疑问,这份词向量 在整个多层神经网络结构中,扮演的是输入的角色还是第一层参数的角色?如果是第一层参数的角色,用BP调优可以影响到这个词向量矩阵里的值吗?
是参数,调优的时候会修改的。
也就是说,相当于一个one-hot向量乘以词典矩阵,作为输入的第一层?
或者说直接就对词向量的每一个输入来求偏导,来修改值?
这两种理解都对的
你好,我和你的理解差不多,每个词的one-hot向量乘以词典矩阵,会得到一个词向量,作为输入的第一层。但是问题是:这个词向量刚开始是随机初始化的,我们bp的时候从后逐层往前,到这一层,怎么更新这个词向量呢?能不能给我个公式推导的详细说明?
bp的时候每层算一个delta,一直递推算到前面就可以了。可以看一下原始论文,写的比较形式化。
写的非常好,期待第二篇!
请教一个和王国昱的问题相关的问题:word—>vecor的第一步应该是将单词(word)表示为某种向量,然后才能以之为模型的输入数据(模型也不认识单词啊)—这里的向量是“one-hot”吗?
没在原文中你引用的这句话。按照你的描述,应该是one hot
写的很不错,受益匪浅
最近google的word2vec是不是也是这方面的?
是这方面的,word2vec是文中提到的Mikolov的新作。
用RNNLM训练了个语言模型,结果连里面的数字代表什么意思都没搞懂,和常用的SRILM等完全不一样,请问有没有介绍 RNNLM Toolkit的资料
是指模型文件里的数字吗?那些都是神经网络的参数。我知道的资料也都局限在那个网页里。
好的谢谢
写得真不错,期待后续文章。
目前关于神经网络用于语言建模的文章中,rnnlm的性能要由于nnlm,普遍的说法是,rnnlm能使用更长的历史信息,但是Milokov在[1]中提到使用梯度下降的训练方法会导致较长的信息难以学到,也就是说,如果nnlm使用的N够大的话,那么效果应该与rnnlm相当,但事实上并非如此。那么是不是可以推测rnnlm性能好与nnlm的关键原因是rnnlm能更好的表示历史信息,特别是变长的历史,而nnlm的历史只是前N-1个词,且是固定不变的,在自然语言中,两个长度差别很大的词串极有可能比两个长度相等的词串相似程度更高。请问博主对这个怎么看,有没有重点讨论这个的工作或paper
个人认为有两点。
首先RNN的表达能力强是有理论依据的(Hinton的神经网络课程里有提到),因此极限情况下,RNNLM可以表达比NNLM更多的信息。
第二个就是优化的问题。RNN用单纯的SGD优化效果一般,梯度传递三层几乎就没了,于是NNLM理论上往前开三个窗口能有类似的效果。但是在操作中,NNLM继续加大窗口,变量数量变得过多,更容易过拟合,RNNLM变量少一些(也可能只是因为变量放在了合适的位置),过拟合稍微轻一些。变量的位置会影响过拟合的程度,一般改模型的论文都在做这个事情。
没见到讨论这个的文章,可能跳出NLP的圈子找找可以找到相关工作。
补充参考文献
【1】Mikolov T, Zweig G. Context dependent recurrent neural network language model[C]//SLT. 2012: 234-239.
Hi, I am a big fan of you, and I want to learn NLP, please send to : caojingdongsb@gmail.com
期待第二部!
膜拜!一直在做传统NGRAM, 没有神经网络基础,看的似懂非懂!楼主能推荐一些资料吗?
参考文献里的几篇论文都比较经典。可以先看看Bengio 2003的那篇。如果直接想当工具包用的话,最好用的是RNNLM。
word2vec 和RNNLM 有什么不一样?
RNNLM已经可以完成词语向量化的工作了啊
目的不太一样,RNNLM主要是想做语言模型;word2vec的本身目的就是训练词向量,速度会更快一些。
可以将输入层到隐层的连接权重U看作是词的向量化,同时隐层到输出层的连接权重V也可以看作是词的向量化,效果如何有待实验的比较,且任务不同,比较的结果也会不同
真是感谢博主,让我学习了很多。因为我是这方面的初学者,所以看了之后有个很初级的问题想请教一下。Bengio 提出的经典训练模型是基于前N-1个词向量来推测第N个词,在实际操作中假设N=5,一句话里面的前4个词的词向量怎么推测呀?
有个专门的“起始”符号。
P(第1个词 | 起始 起始 起始 起始)
P(第2个词 | 起始 起始 起始 第1个词)
大概是这个形式
原来如此,非常感谢
赞一个,期待续篇
写得真好!期待第二篇
这个如此清晰的概述般的捋顺,对于我这个初学者来说,真是获益匪浅,多谢博主无私分享,期待第二篇。
大赞博主
“可以简单地设想一下把网络的最后一层变成一颗平衡二叉树,二叉树的每个非叶节点用于给预测向量分类,最后到叶节点就可以确定下一个词是哪个了”
楼主能详细解释这句话吗?为何二叉树的每个非叶节点可以预测向量分类,同时到叶子结点就知道是哪个词?
同时是不是word2vec项目里用huffman树也是为了解决这个问题的?看你的文章主要是想得到在word2vec里使用huffman树的原因。
word2vec里面的huffman树也是做这个用的。语言模型由于要求概率值,最后那层会用softmax。朴素的softmax计算复杂度太高。这种树形结构叫做hierarchical softmax,可以用少量的计算得到概率值。
http://arxiv.org/pdf/1310.4546.pdf 这篇文章对word2vec的细节讲的比较清楚,可以参考一下。
楼主,您好!最近一直关注word embedding方面的研究,现希望做一些中文词向量方面的研究,注意到您们的《基于表示学习的中文分词算法探索》已在CNCCL上发表,不知道楼主能不能提供论文的下载地址供大家学习研究。。。谢谢了!
我不确定论文能否直接放在网上,可能有版权问题。已经发到你的邮箱。
能否也发一份给我
已发
楼主您好!《基于表示学习的中文分词算法探索》这篇论文可以给我发一份吗?谢谢啦!
已发
同求,谢谢!
已发
同求楼主的《基于表示学习的中文分词算法探索》,多谢!
已发
《基于表示学习的中文分词算法探索》是用词向量或者类似方法来进行分词吗? 听起来很有趣的样子,麻烦博主也给我看一下论文吧
是的,论文已发
同求楼主的《基于表示学习的中文分词算法探索》,多谢!
已发
博主,能给我发一份吗?学习学习。。谢谢
已发
楼主的《基于表示学习的中文分词算法探索》可以发一份吗,谢谢~!
现在网上能直接搜到了
licstar,您好,发给我一份好吗? 谢谢!
已发
楼主您好!《基于表示学习的中文分词算法探索》这篇论文可以给我发一份吗?谢谢啦!
已发
博主你好,最近一直在看deep lesrning 在文本分类上的研究,但不知该具体做那个方向的研究,希望楼主提供一个创新点,或者突破口。。。谢谢
这个我也比较迷茫啊,还没找到好的点……
楼主您好,可否把您的论文《基于表示学习的中文分词算法探索》也给我发一下?
已发
博主大大能不能给我发一份 , 谢谢大大
现在网上能直接下载到了,论文标题搜一下就有。
http://www.cips-cl.org/static/anthology/CCL-2013/CCL-13-095.pdf
楼主您好!我想问下如果有两个长度为N语言片段,在利用N-gram时,如果第N个词汇相同,而前面N-1个词汇不尽相同,那么针对第N个词汇训练的词向量,应该如何表示?另外,能否把您的论文《基于表示学习的中文分词算法探索》也发给我一份,多谢。
论文已发。
前N-1个词和第N个词构成一个样本。前N-1个词变了之后,即使第N个词不变,也换了一个样本。用随机梯度下降法优化的话,每个样本都跑一遍就可以了。
楼主您好!请问词向量的每个维度代表什么?比如一个词的向量[0.792, −0.177, −0.107, 0.109, −0.542, …]中0.792表示什么意思?或者维度的含义和什么有关?非常感谢您的回答。
我的理解是每个词的特征,不知是否有更深层次的理解?
这些维度描述了词的隐含语义,可以理解为特征。具体到一个维度,目前还没见到比较好的解释。
这个问题真搞笑
hi,由于词向量一般作为另外系统(比如chunking ner什么的)第一层参数的初值,感觉相当于把第一层的参数预先调整得离最优解较近,类似deep learning在第一层做greed layer-wised learning?
那么结论会不会是,如果用词向量作为另外系统第一层参数初值的话,不同的方法学到的词向量差别不大?(因为这些词向量都已经离最优解较近了)
确实很像deep learning在图像里面做的无标注学习。
个人感觉不同方法学到的词向量还是有点差别的。从HLBL和C&W融合之后效果可以更好看,应该这两种方法都不能算接近最优。
您好,我还有一个问题,词的向量化,从数学上看的话,相当于把binary feature映射为高维实向量,有没有不是word的binary feature 实向量化的文献推荐?
这方面我还没有了解过。是个很好的思路。
楼主你好! 也想一睹《基于表示学习的中文分词算法探索》一文,可以发到邮箱吗?谢谢!
已发
楼主,真心赞。同求您的论文,拜谢!
已发
恳求楼主也发一份
大棒了!
写的很好。就是有一个地方是不是写错了:最后希望正样本的打分要比负样本的打分至少高 1 分。
根据loss function,1-f(x)+f(x(w)) > 0,变换之后应该是f(x)-f(x(w))<1。所以优化目标是使正确短串的score最大,错误短串的score尽可能小,约束条件是正确短串的score比错误短串score至多高1分。
1-f(x)+f(x(w)) > 0 这里应该是<0吧?是要最小化目标函数,而不是最大化目标函数。
1-f(x)+f(x(w)) <0,但是目标函数是:max{0,1-f(x)+f(x(w))}, 而目标又是最小化目标函数,这里是不是矛盾啊
不矛盾吧,max可以看成一个小于0就截断的操作,不影响最小化
你好,我也有同样的疑惑,请问你理解了吗?
感谢作者的整理,如果能写成综述文章的话就可以引用啦~那样或许会发挥更大的价值~
博主威武。收藏学习
博主牛啊!入门word vector就靠你的了。有个问题请教一下,bengio 03文章里面的NN结构我不知道理解的对不对。是不是一个4层NN,输入是一个向量,有两个隐含层,输入到第一个隐含层的权值矩阵就是vector?
另外,同求你的论文《基于表示学习的中文分词算法探索》!
是的,你的理解很对。也有人喜欢理解成三层的网络,把词向量当作第一层,跳过了矩阵中映射的那层。
论文已发。
输入到第一个隐藏层的权值怎么会是Vector?不可能权重是词向量吧。我认为初始输入是词向量并且作为参数输入,SGD不仅优化输入到隐藏层的W和b,隐藏层到输出层的W和b,还优化最初的输入层的参数。真正的词向量蕴藏在输入参数当中,并不是权重矩阵。
输入的是各个单词的One -hot特征矩阵X ,进过词向量特征矩阵W映射转化后连接隐藏层神经元
求论文:基于表示学习的中文分词算法探索。谢谢了。
已发
博主您好,求一份您的论文《基于表示学习的中文分词算法探索》。不甚感激。
博主您好,求一份您的论文《基于表示学习的中文分词算法探索》,谢谢。
已发
赞一个。
期待续篇。
听过楼主讲课.求论文:基于表示学习的中文分词算法探索,谢谢.
已发
我也要,谢谢楼主!!!!zwphumor@163.com
已发
期待下一篇博文快快发表.
1. 写的真好,拜读了。
2. 期待 Deep Learning in NLP (二)模型及用法
3. 求基于表示学习的中文分词算法探索论文,谢谢。
多谢。论文已发。
“作为辅助特征扩充现有模型。如 Turian 将词向量作为额外的特征加入到接近 state of the art 的方法中,进一步提高了命名实体识别和短语识别的效果。
具体的用法理论上会在下一篇博文中细讲。”
期待下一篇,弱问 “扩充特征” 具体怎么做有效果?
将所有词的特征向量求和得到句子的特征向量吗?
那两个任务都是做序列标注的,特征都是一个窗口里面的词。所以把窗口里的词向量作为辅助特征加上就可以了。
里面有很多调参数的技巧,提升稀疏特征和稠密特征一起用的效果。具体看他原来的论文吧 Word representations: a simple and general method for semi-supervised learning
博主 你的基于表示学习的中文分词算法探索论文能发我学习下 谢谢
已发
博主的文章写得深入浅出,相当精彩,读后觉得收获很大,大赞,谢谢你的总结和分享。求文章《基于表示学习的中文分词算法探索》,继续学习!
谢谢,论文已发
博主您好,我想实现一下您论文中的那种神经网络模型,请问您用的sighan2005的数据集在哪里能下载到?谢谢!
数据见 http://www.sighan.org/bakeoff2005/
博主,我最近在看关于RNNLM的那篇论文,有一点不大清楚,这个工具包训练得到的词向量是y(t)还是什么具体的?训练部分得到的词向量存在了哪里呢?是保存着在他保存网络结构的那个文件里么?
Mikolov的回信,转自微博 @老淘
You need to add this function to rnnlmlib.cpp and call it to generate the file with word vectors:
void CRnnLM::writeVectors() {
FILE *fo=fopen("word_projections.txt", "wb");
int a,b;
restoreNet();
fprintf(fo, "%d %d\n", vocab_size, layer1_size);
for (a=0; a
您好,我是一名学生,我想知道Mikolov的RNNLM toolkit中如何将训练好的词向量保存到文件中,您能告诉我一下吗?万分感谢。
现在直接用word2vec就可以保存到文件了,自带这个功能。RNNLM也可以模仿word2vec的保存文件的代码,类似地写一个,换一下变量名就行。
Mikolov的回信,转自微博 @老淘
You need to add this function to rnnlmlib.cpp and call it to generate the file with word vectors:
void CRnnLM::writeVectors() {
FILE *fo=fopen("word_projections.txt", "wb");
int a,b;
restoreNet();
fprintf(fo, "%d %d\n", vocab_size, layer1_size);
for (a=0; a
博主,你好!我想问一下,在不同的文本中,对同一个词的相同维度的分布式表示,是否有可比性?比如在A文本中,词x表示为=[a1,a2,….,an],在文本B中,词x表示为=[b1,b2,…,bn],这两个向量是否可以比较?希望可以指点。谢谢!另外,同求论文<>!
一个词一般只有一种表示,不管在哪个文本中都是一样的表示。
当然,如果训练语料变了,词向量也会不一样。不同训练语料得到的词向量可能具有线性变换的关系。可以参考这篇论文:http://arxiv.org/pdf/1309.4168.pdf
第一部看了很受益,楼主不忙了,策划第二部吧。等的真着急。
博主,您好,看了懂了很多
想请问bengio NNLM有没有toolkit release?
想当作baseline来比较其他任务。
另外关于RNNLM,博主提到sigmoid 函数似乎不够力?
那换成hyperbolic tangent或者其他? 比较牛?
RNNLM优化函数SGD,现在其他方式的优化方式
速度和效果都不错的?
谢谢
NNLM我没见到代码。
RNNLM里不是说的sigmoid函数会导致效果不好,只是作为词向量感觉怪怪的。
要做语言模型的baseline的话,可以选RNNLM。如果是词向量的baseline,可以选word2vec。
我有个问题不明白,如何同时优化神经网络的输入层和输出层呢?最初的输入层如何确定?
只优化输入和隐藏层,不优化输出层的。可能你说的是隐藏层?
用SGD的思想去考虑这个,目标函数对各个变量求偏导,就知道每个变量应该怎么修正了。输入和隐藏层都是这样。
最初的输入层也是随机初始化的。
请问楼主最初的输入是不是随机的啊
是随机的
个人觉得最初的输入是单词的one-hot特征,是已知的,输入为one-hot特征矩阵X ,模型假设每个单词存在一个词向量,那么存在词向量矩阵W,那么隐藏层为S = sigmod(XW+b)
期待第二部哦,受益匪浅
最近看到大家已经开始用词向量做分词,pos,ner的各种task了,顺便求论文膜拜
论文已发
非常好,感谢分享,喜欢lz继续写后续文章。
同求论文,谢谢。最近用word2vec训练了一个特殊的语料库,有很多术语的,本来期望有很多线性平移的部分(因为术语有很多相关),但结果似乎不好。是不是和术语本身的高度相关定义(但不是多义)有关?
语料库的规模多大呢?太小的话可能效果有限。如果大了也不好的话,可能就是新发现了。
Good job!
Benjio03的模型中,为什么直连边可以减少一半的迭代次数?
这个我也不知道为什么,是他论文报告的实验结果。
我的理解是:因为直连边把loss直接传递给了词向量层,加速了词的二进制特征到词向量计算时,那部分神经网络权值的更新速度,所以,用更少的迭代步数,可以更快的训练出生成词向量的矩阵。
个人感觉今年学习语句向量的研究多了起来,《A Convolutional Neural Network for Modelling Sentences》,《Distributed Representations of Sentences and Documents》两篇文章都取得了不错的效果。期待博主的Deep Learning for NLP (二)
博主,希望拜读论文《基于表示学习的中文分词算法探索》,能否发我一份?谢谢~
已发
楼主的这篇文章我拜读了一遍又一遍,对我这样初入NLP的人来说,视为至宝!感谢楼主的热心奉献!
现在在读Bengio 2003,读的一知半解,初始的词向量是怎么选择的?期待楼主的新作,会一直关注你的博客~
初始全是随机数。之后当成普通的参数来优化。
希望拜读下楼主的论文,《基于表示学习的中文分词算法探索》,希望楼主给我发一个。谢谢!
已发
楼主我又来看你了。
最近,看了几篇语言模型方面的经典论文之后产生了几个问题,希望能和作者探讨一番。其中一个是关于神经网络目标函数合理性方面,我写了个note(附件some details.pdf)(由于不知道楼主邮箱,所以贴个百度分享链接哈,http://pan.baidu.com/s/1ntidfEp),也可能是我的思路哪里局限住了。还有一个是我关于RNN LM梯度的一个推导(附件 Statistical Language Models based on Neural Networks.pdf),楼主能否帮我看下是否合理。
很佩服作者的开源精神,我也十分希望能将自己做的一些东西给大家提供一个借鉴,毕竟如果每篇论文都从头读起,也是相当费工夫的。
我还没看你对RNNLM的梯度推导。先说一下前面那个问题。
首先,你的note里面的推导应该是没问题的,你提到的神经网络的目标和RNNLM的交叉熵哪个更合理。其实神经网络模型的目标也是交叉熵。你式子里的 m_i log(p_i) 这个就是交叉熵的公式。RNNLM用的也是这个,可能只是写法不一样,其实都是交叉熵。
神经网络模型和n-gram的区别在于对context的建模上。如果从目标看,就和你分析的一样,都是希望p能够逼近统计量m。但是n-gram只是简单的统计m,直接作为p(用你写的式子),神经网络模型则是用了一个神经网络来计算p,利用m作为训练数据,使得神经网络模型尽可能接近我们希望的p。这样主要好处是可以降低数据稀疏的问题(比如低频词,再比如n-gram里面n很大的时候)。
楼主您好,我想问一下distributed representation和distributional representation的区别?谢谢~
我的理解是,很可能这两个本质上是一样的。distributed是神经网络模型算出来的,统计模型算出来的叫distributional。以上均是个人理解。
膜拜中,也希望拜读楼主的论文:《基于表示学习的中文分词算法探索》,谢谢!
已发
膜拜中,也希望拜读楼主的论文:《基于表示学习的中文分词算法探索》,谢谢!
已发
hi 博主你好,非常高兴认识你! 我最近在读您的那篇deep learning in nlp的博文,我觉得非常有用,很感谢你花时间,给我们介绍deep learning in nlp的相关知识!看了博文之后,我又阅读了一些原文,在读collobert jmlr2011论文的时候,有一些不理解的地方想向您请教!关于sentence leve loglikelihood 为什么可以用viterbi算法解码呢?每一步的网络输出 f(theta) 都是和之前几步的决策相关的,因为要从前几步决定的tag中抽取特征,不知道这里我有没有理解对,希望能够获得您的解答,谢谢啦!
我的理解是,他的公式14、15是一个递推式,可以用viterbi算法来算这个递推,从t=1一直推到整个句子。
博主对 Word2Vec 及其相关模型,解释得深入浅出,非常棒。
请教博主,对 LSTM (Long Short Term Memory)怎么看?
假如想做句型分析,用 LSTM 好,还是用 Word2Vec 的套路好?所谓句型分析,举个例子。
输入: “患者自述咳嗽三月余,浓痰,夜间加剧”。
输出: { Symptom:“咳嗽”, Duration: “3 months”, Extent: “浓痰” } # 对于无法识别的部分,如 “夜间加剧”,则忽略之。
多谢。
另外,
1. 期待 Deep Learning in NLP (二)模型及用法
2. 求 “基于表示学习的中文分词算法探索” 论文
谢谢。
仰慕邓侃大神!
看起来这比较像序列标注,LSTM应该比较适合做序列标注。
我不清楚你说的word2vec套路做这个,是怎么做,一般我只见到用word2vec做神经网络的初始化,和LSTM或者别的模型不矛盾。
P.S.我们有人在尝试用CNN做类似问题。
楼主您好,希望拜读楼主的论文:《基于表示学习的中文分词算法探索》,谢谢!
已发
楼主,您好。谢谢您的博文,关于Deep learning for NLP,我从您的文章中学习到了很多。最近看bengio 的文章感到困惑,特别是他的目标函数中的T表示困惑,T是指训练语料所有的句子还是n元连续文本片段,请博主给与解答,谢谢博主。
应该是n元短语片段。
同求论文《基于表示学习的中文分词算法探索》,现在初步接触这个领域,顺便想弱弱得问一句lz目前在哪工作或者读博啊
已发。在中科院读博。
word2vec中skip-gram,用NCE优化,稳定吗?就是给不同的初值,生成的词向量差异大吗。其实我不太知道如何衡量它的鲁棒性
从数值上看,差异会非常大。因为局部最优解有很多,每次随机肯定都到不同的局部最优解。如果做任务,比如类比,看king-queen=man-woman的准确率,这个数值还是相对稳定的。
你好 写的很好
对于词向量如何得到的不是太懂。
“所有训练方法都是在训练语言模型的同时,顺便得到词向量的。”
刚开始的词典矩阵是怎么得到的呢? 词向量只是取其中一行吗?那就已经是提前训练好的实数值吗?还是one-hot向量呢,若是one-hot向量,训练的时候怎么会变化呢?
谢谢
一开始是随机初始化的实数值,不是one-hot。基于迭代的机器学习模型基本都是先随机初始化,然后用迭代方法逐步优化。
请问在使用word embedding解决相关问题时,对于训练预料中未出现的词的词向量一般如何处理?
SENNA的处理方式是,低频词、未知词全都用一个特殊的*UNKNOWN*代替,所有的未知词都替换成这个。对于英语也有一些利用词根的方法,训练词根的embedding,然后合成整个单词的语义。中文或许可以用字吧。
感谢博主分享,也希望拜读您的论文:《基于表示学习的中文分词算法探索》,另外自己刚开始学这方面的知识,写了一篇Bengio(2003)的NNLM论文的笔记(http://blog.csdn.net/a635661820/article/details/44130285 ),包含公式推导以及简要实现(c++代码),可能有许多理解不正确的地方,希望能和大家一起学习交流,共同进步~
论文已发,期待交流。
求您的论文,基于表示学习的中文分词算法探索
已发
这篇文章讲的特备好,受教了。现在会使用RNNLM toolkit,但是我想将RNNLM应用到机器翻译中,得出BLEU得分,我应用的是Moses平台,不知道应该怎么做,我的想法是将RNNLM产生的model编程SRILM的格式,不知道这样想对吗?
我不做机器翻译,这方面不了解。你可以直接发邮件询问Mikolov,他一般都会回复的。
博主,能否给一份此博文的PDF版本?非常感谢
抱歉,没有做PDF版本。
楼主您好,希望拜读楼主的论文:基于表示学习的中文分词算法探索,感恩!
已发
楼主写的很好,能否把您的论文《基于表示学习的中文分词算法探索》也发给我一份?谢谢了
已发。
楼主您好,正在做这方面的研究,希望拜读楼主的论文:基于表示学习的中文分词算法探索,谢谢
已发
也希望拜读楼主的论文:《基于表示学习的中文分词算法探索》
多谢!
已发
同求楼主论文《基于表示学习的中文分词算法探索》!
已发
拜读了,受益很大。期待后续的文章~
写的真是浅显易懂 老少皆宜
PS :也希望拜读楼主的论文:《基于表示学习的中文分词算法探索》
多谢!
已发
期待出(二),顺带讲讲word2vector吧~~~
读了博主的这篇文章受益匪浅,不过还有几个问题:
在“2.3 M&H 的 HLBL”中,博主如何等价出对应的神经网络公式的?
文中提到了“于是语料中最长的句子有多长,就会有多少个 H 矩阵。这显然是过于理想化了。最后在实现模型时,还是迫于现实的压力,用了类似 n-gram 的近似,只考虑了上文的 3 到 5 个词作为输入来预测下一个词。”
我看原文中是第二个模型提到了用多个H_i,感觉博主说的应该是第二个模型:The Temporal Factored RBM啊,
第三个模型Log-Bilinear Language Model中原文说了没有隐含层啊:“directly parameterize
the distribution and thus avoid introducing stochastic hidden variables altogether.” 我看公式感觉就是对上下文词向量与当前词向量的线性组合啊。
另外如何理解RBM和神经网络以及他们的训练方法。我原来理解是他们是不同的方法,如果将RBM训练的隐藏层参数作为初始值训练神经网络,相当于特征提取。二者还有什么其他联系吗?
想听听博主高见?
还有为啥Log-Bilinear Language Model好?它train以及test时候是不是也是需要计算全部词表的概率?它简化训练时间是不是因为减少隐藏层的关系?
这个我也不理解,他的论文里是这么说的,应该只是实验结果吧。
需要计算全部词表的概率。
LBL没有神经网络的隐藏层,但是我觉得和隐藏层差不多了,只是少了个非线性的激活函数。
第三个模型的C_i就是每个词有一个的啊
不知道你说的线性组合是什么意思。双线性模型属于你说的线性组合吗?
RBM那几个模型我没去深究,不太好评价。
http://blog.csdn.net/zhoubl668/article/details/23271225#comments
在CSDN看到了这篇。呃,博主,这是你的博客?不是的话我友情举报了:)
233被全文引用了。。
博主好!非常感谢对NLP的系统性的入门指导~!
我正在做天池的新浪微博预测大赛,其中微博内容的处理部分非常地需要词向量的帮助。因为对于nlp我几乎完全是门外汉,所以有一个可能很小白的问题想请教一下您,RNNLM和word2vec的区别是什么?如果我使用在新浪微博上的话,是不是选其中一个就ok,效果都差不多捏~?
另外,如果能拜读一下博主《基于表示学习的中文分词算法探索》大作就更好啦~~先提前感谢~
这两个模型区别还挺大的,新浪微博抽特征的话就用word2vec吧。
论文已发。
现在刚开始看词向量相关的,求楼主论文《基于表示学习的中文分词算法探索》!
已发
感谢楼主的分享,希望能拜读一下博主的《基于表示学习的中文分词算法探索》,先谢谢了
已发
现在博主是在用CPU+多机训练还是GPU训练呢?
CPU+多机。word2vec的原始版本效率挺高的,就直接在这个基础上改了,所以CPU上好做一些。
拜读了,对于本人的研究很很大启发!感谢楼主!期待楼主的后续文章!
另外,如果方便的话,不知能否烦请楼主,发一下您的大作《基于表示学习的中文分词算法探索》,可以让我拜读学习!非常感谢!
邮箱:404541911@qq.com
拜读了博主的大作,受益匪浅!期待博主后续的作品!非常感谢!
另外,不知能否麻烦楼主,方便发一下您的论文《基于表示学习的中文分词算法探索》吗?
本人邮箱:404541911@qq.com,非常感谢!
已发
博主写的很好。我有一个问题,LTSM比RNNLM出现的早,在语音,nlp的一些问题上也超过了RNN,为什么现在才火,这两种方法在应用中有哪些差别?
90年RNN,98年LSTM。然后00-05年的时候SVM、CRF这类模型占上风。06年开始神经网络又开始火了,又是一个轮回。
其实LSTM的研究和应用一直没断过,0几年的时候也有不少文章,只不过没用深度学习的名头来说。一直做神经网络的人也很清楚LSTM相比朴素RNN的优势。Hinton在coursera的公开课里就提到了LSTM,那个时候LSTM还没现在这么火。
我觉得区别就是朴素的RNN代码写起来稍微好些一点;LSTM解决了朴素RNN梯度衰减的问题,效果会好一点。
感谢楼主的分享,希望能拜读一下博主的《基于表示学习的中文分词算法探索》,先谢谢了!
已发
感謝樓主分享,有兩個問題想請問一下版主
(1).w 到 C(w) 的转化就是从矩阵中取出一行,請問是取出一列還是一行,因為這裡矩陣的行表示的好像是|V|
(2)想請問版主是否會有人將w轉化成矩陣的時候表示為projection 層
最後希望可以拜讀楼主论文《基于表示学习的中文分词算法探索》
(1)这个其实不重要吧,如果矩阵是|V|行,那就是取一行,如果有|V|列,那就是取其中一列。
(2)有些工作确实把这个叫做projection层,这样看起来层数就多了一层。
论文已发。
我是来膜拜的,期待连载
弱弱的问一下,这个词向量应该就是通常深度学习模型做Embedding初始化了,然后看了下那个word2vec也是对词做向量化,是不是两个一样的?或者如果做了word2vec模型开始就不需要Embedding了?
word2vec就是这里面涉及模型的改进版,都是生成embedding的模型。这篇博客写的比较早,当时word2vec还没发布,所以没有提及。你可以参考我这篇新的:http://licstar.net/archives/620
楼主您好,可否把您的论文《基于表示学习的中文分词算法探索》也给我发一下?谢谢!
网上已经有了:http://wenku.baidu.com/view/4927de52bb68a98270fefa31.html
博主,词向量间能体现出语序信息吗?
举个例子,我在Google搜索 kobe
Google会弹出一个框,而kobe bryant排在第一。这个在统计语言模型好实现,想问下词向量间有这种关系吗?
skip-gram和cbow这两个模型没有前后顺序,别的好多模型有,比如NNLM。
想请教一下博主,词向量映射的具体过程是怎样的?语料中的词汇数不胜数,而词向量维数却只有50维的话,在检视目标词的窗口时,其具体过程是怎样的?还望指教。
每个词有个词向量,对应查表就可以了。
看到2.1节用神经网络训练语言模型的时候有一个小小的疑问,请问一下博主。
1.因为训练词向量的大体思路是用Wt的前n-1个词(上下文信息)作为输入,放入到神经网络中去训练,得到第Wt个词的词向量,但是这前n-1个词的词向量是怎么来的呢?
2.“C(w) 表示词 ww 所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵 CC(一个 |V|×m|V|×m 的矩阵)中。其中 |V||V| 表示词表的大小(语料中的总词数),mm 表示词向量的维度。ww 到 C(w)C(w) 的转化就是从矩阵中取出一行。”我理解这里的矩阵C就是存储第w个词的词向量C[w],但是它是不是也是训练出来的呀?那最开始的n-1个C[1]…C[n-1]是怎么得来的呢?
好困惑,希望博主帮忙解释下!谢谢。
每个词都有一个对应的词向量,随机初始化。使用的时候不管是前n-1个还是第n个都是直接从矩阵中找到对应的行得到的。
我也有这个问题,感觉有点像牛顿迭代法,每个词从初始随机向量,慢慢迭代到最终的词向量
是的,现在主流机器学习都是用类似的方法的。先随机初始化,然后慢慢迭代优化。
对于word2vec原理了解帮助很大!梳理得较全面!另求博主的论文《基于表示学习的中文分词算法探索》,O(∩_∩)O谢谢!
论文网上已经有了:http://wenku.baidu.com/view/4927de52bb68a98270fefa31.html
最近看了很多关于“词向量”的东西。有一个问题始终萦绕心头:词向量代表的是什么?是那个最为“形状”的词,还是“语言”本身?是那个指代“语言”的符号,还是那个符号背后的什么东东?“词向量”本身不是符号吗?作为形状的“词语”不是符号吗?用一种更简单的(例如数字)去替代“语言符号”这种本身就比较复杂的系统的符号,真的能捕捉到要捕捉的东西吗?恐怕计算机专家们和数学家们把这个问题想得太简单了。
因为计算机只能处理数据,所以必须把文字映射为数字才可以。
最初的词向量是用id来表示,用id来表示只是简单描述了词的形状,并没有表示词与词之间的关系(意义)。
词向量根据词与周围得关系(出现频率)优化出来后,就表示了一定词的意义。比如同义词的词向量的斜率很接近。所有的动词的向量的斜率会限制在某个范围内等。
当然,现在只是考虑了词的相对出现频率,来得到词向量。如果能把词向量与影相对应一下,应该会更好。(影相的特征就取深度网络的feature map,有人在研究计算机的看图说话,我么这边就可以把图的特征加入到词向量的训练中)
个人粗浅理解,欢迎拍砖。
支持你的想法。我也觉得语言最终应该对应到现实实物中才能真正用起来。
请问C&W方法和HLBL有训练代码吗?博主给的链接里只有训练好的词向量呢
有一个我自己实现的版本,可以参考这篇博客:http://licstar.net/archives/620
受益良多,期待下一篇,希望能拜讀博主的《基于表示学习的中文分词算法探索》,謝謝!
论文网上已经有了:http://wenku.baidu.com/view/4927de52bb68a98270fefa31.html
谢谢楼主,给我这个自学的菜鸟指导了方向,之前就一直再看HMM,CRF算法啥的,看完也不知道该干啥。。。
博主,您好!最近在做文中自动纠错放方面的研究,请问词向量与这方面有没有比较好的切合点,请给出一些建议,谢谢!
语言模型应该是可以用来做纠错的。具体我也没研究过这方面,不知道现有的方法是什么样的
文章写的好有条理,赞!
博主您好,在您文章的第2.1节中指出了U是一个|V|×h的矩阵,这我没有搞清楚h是谁的参数呢?
另外,我刚上研究生,最近想做些有关于这方面的学习,从哪里得到在词向量方面最新进展研究的情况呢?
哦,我好想明白了,看了下面的内容,h是隐藏层的维数,对吗?
对
感谢博主,其实心中带着疑问来看的,这个文章完美的解决了我的问题。这篇博文还带我浏览了前辈们在词向量和语言模型方面的研究和思路。
这里,我觉得后面用深度网络来训的时候,词向量的初始化不一定非要随机,也可以把前人得到的此向量拿来做初始化,感觉收敛应该更快,也可能训练出更好的词向量,语音模型。
期待楼主下一篇。
楼主论文我已通过网络获取,多谢。
good!
博主您好,你的文章写的非常好,让我们初学者什么受益,可以问一下您是在那工作吗?谢谢。
腾讯
老师您好,我是初学者,有很多困难,能给我一下您《Recurrent Convolutional Neural Networks for Text Classification》的代码吗?非常感激,我邮箱(272000963@qq.com),谢谢
已经放到http://licstar.net/links
你好,我想问下中文中的罕见词和未登录词通过word2vec训练后得到的词向量效果好不好?有没有什么好的处理办法?
一般如果语料里出现小于5次的(也有人说100次),训练起来效果都不太理想。低频词前几年的处理方法是全部用一个特殊符号代替,所有的低频词都用同一个符号。这一两年我没跟进了,不太了解新进展。
谢谢好文。但是博主的文章似乎被这些人抄了
http://www.xml-data.org/JSJYY/2016-36-10-028.htm
这个不算抄吧,既没有重复的文字,想法也是新的……
您好博主,我一直有个疑问。请问如果对Wi这个词进行预测,那么这个词的前n个词的词向量是如何得来的呢?
前n个词的参数和Wi这个词的参数是同时学习的
来老师,您好! 仔细拜读了您的博文及博士论文,收获良多,感谢老师诚意分享~~有一个问题想请教您:关于Minkolov公开的那个RNNLM toolkit,我看了给出的一些example以及相关的一些说明文档,但还是没太搞清楚这个toolkit中生成的词向量的位置是在哪儿,但官网却给出了用RNNLM训练broadcastNews产生的词向量……所以想请问下来老师,假如用这个toolkit读入自己的语料,该如何得到词向量呢…… 冒昧打扰,还请见谅!盼回复,谢谢您!
里面的隐层就是词向量
楼主您好 看了您的文章,我真的觉得学习到了很多(肺腑的)。我在做聚类,求微博文本之间的相似度。我现在在用word2vec做词向量,然后求平均值来作为微博句子的句子向量(已做过doc2vec,效果比较差),然后计算微博之间的相似度来聚类。请问您能给点建议吗?或者推荐些资料,或者说换求词向量的方法。感谢楼主
一方面我觉得你可以试试LDA,做文档级别的事可能比词向量效果好。另一方面我觉得聚类这件事情本身就不可预期,可能其实他也是一个很好的聚类,只不过不符合我们的预期。如果有条件的话找点标注样本当作聚类中心,或者直接用分类试试。
博主你好,看了你的博文受益匪浅。我有个问题想请教:在最初时,是将各个词的词向量随机初始化,然后利用梯度下降的方式,最终获得训练好的词向量吗?
是的
博主你好,还有2个问题想请教,第一,神经网络训练语言模型的时候,一般误差是以什么形式表达的呢?输出层输出的不是一个n维的向量吗?每一维Oi表示下一个词为wi的概率,选择概率最大的作为最后输出,那怎么定义误差来调整参数呢?第二,训练后得到的词向量是隐含层和输出层的权值矩阵吗?因为这个矩阵才是n行的,每行刚好可以表示一个词的词向量。而输入层和隐含层的权值矩阵未必是n列的。请问这样理解对吗?
感谢楼主的分享,楼主能否发一份博士论文,拜读一下!
http://pan.baidu.com/s/1jGWmmZO
你好,我看了一下你的博士论文,有个地方有点疑问想请教一下,论文2.2.2部分提到,如果采用独热表示,则是一个|V|的n-1次方维的向量,空间非常稀疏,为什么是n-1次方?不是|V|*(n-1)维吗?
独热表示,如果词典有10个字(0-9),构建tri-gram就是从000到999,一共1000种情况,而不是10*3
来博你好,我在维基百科的上进行实验,只针对size和iter,发现确实300size,30iter已经差不多。但是实验室计算资源和时间有限,请问一下你的经验,我需要在得到较好的semantic accuuracy,sample,window,threads,hs应该如何取舍
hs=0,threads看机器性能吧,window其实依赖于你的任务,我一般用5.
最好的方法还是看在你需要的那个应用上的效果
你好,请问你在用glove训练wordembeding时,选择的迭代次数为多少比较合适
10-50次,根据自己的任务要做调整
请问 NNLM模型中,输入为条件部分的整个词序列:wi−(n−1), . . . , wi−1,输出为目标词的分布(V个值),最后需要最大化目标函数∑wi−(n−1):i∈D(log P(wi| wi−(n−1), . . . , wi−1) ),那么具体对每个训练样本是只最大化V个值中的第i个(目标词)吗?还有模型的原始文本输入的是词在库中的index吗,最后词向量和index对应上?
// 那么具体对每个训练样本是只最大化V个值中的第i个(目标词)吗?
是的
// 还有模型的原始文本输入的是词在库中的index吗,最后词向量和index对应上?
对
请问还有第二篇嘛 写的很好 受益很多~
估计没有了,当时写的提纲已经基本过时了。现在这方面的资料足够多。可以关注PaperWeekly的公众号
我和楼上有位同学理解有些不一致,他认为输入到第一个隐藏层的权值是Vector?不可能权重是词向量吧。我认为初始输入是词向量并且作为参数输入,SGD不仅优化输入到隐藏层的W和b和隐藏层到输出层的W和b,还优化最初的输入层的参数。真正的词向量蕴藏在输入参数当中,而并不是输入到第一个隐藏层的权重。楼主,我这样理解对么?
两种都说的通吧,如果把词向量看成权重,那权重也是需要当作参数更新的。当作输入层也可以,只要知道词向量会在训练中当作参数更新就行。
谢谢楼主师兄,我们也应该是校友啦,我现在在沈阳自动化研究所读研究生一年级,准备做这个方向,但是现在所里做这个的还是比较少的,所以交流上有些困难,希望能得到师兄指点。这是我的微信或者QQ:1107274398
when to write the article of Deep Learning in NLP (二)模型及用法?
Excellent of blogger!!
额,应该不会写了,当时设想的题目现在已经过时了。
最近要做 评论分类,垃圾评论过滤。 需要了解NLP方面的知识,博主的文章写得真好。我是腾讯视频的,可否加微信 请教下呢?微信号 fengmozhui
期待二。
博主好~文章总结归纳得很好!我想请教几个问题,
1. cbow和skip-gram框架看起来都差不多,实际应用上两者有什么区别吗?孰优孰劣呢?
2. cbow和skip-gram中的输入矩阵和输出矩阵,都可以视作词向量吗(还是只是输入矩阵作为最终输出结果)?
谢谢~
1 可以参考 《How to Generate a Good Word Embedding?》导读 http://licstar.net/archives/620
2 输入输出都可以作为词向量
能麻烦您发我您的这篇文章吗?基于表示学习的中文分词算法探索
现在在入门阶段
现在搜索引擎可以直接搜到这篇文章了
看一次爽一次,每次都有新认识。感谢来博士!
厉害厉害,工作量感觉相当大…很有深度与广度的分享
博主你好!受小白一拜!鄙人稍懂Python,想要入门数据分析与机器学习,求规划学习路线,现在一头雾水,不知从何学起!
可以先看看Andrew Ng的视频课程
博主你好,在Bengio论文中,词向量矩阵C是可以训练的,但是这个C怎么训练呢,论文中是把它作为参数,是对整个矩阵求导吗?另外,这个C中词向量是作为输入的,那么训练的时候这个输入是变化的,那么它的系数矩阵应该也是变化的,它能得到稳定吗?它这个有没有开源的代码呢?
你说的输入变化可能是指每次选取的是不同的词,不过每个词对应的参数向量是固定的,所以训练起来没问题。
我在word2vec的基础上实现过一个近似的版本,供参考
https://github.com/licstar/compare/blob/master/embedding/nnlm.c
很哈搜的呀
SENNA 哪位大侠能提供一下文件,谢谢。我这么无法下载这个文件。
https://ronan.collobert.com/senna/senna-v3.0.tgz
博主你好,百度开源了一个项目,其中有TWE(topical word embeddings)模型,不知博主对这个模型怎么看?TWE算是利用LDA的主题而训练的word2vec吗?如果能讲一下LDA、TWE、word2vec的关系就更好了。感谢!
这方面我不太了解,你可以请教一下TWE的作者。
博主写得太牛逼了,读来简洁易懂非常爽啊!!
不过有一个小小的疑问哈,既然词向量X与作用在X上的矩阵W都视作参数一并迭代优化,而一般情况下输入隐藏层的是sigmod(W*X),那是不是对整个词向量空间{X}做个W逆矩阵旋转W^{-1},就可以消掉第一层的W参数了?
W一般不是方的,不是n*n的
博主你好,有个问题,楼上也有人提到,RNNLM中的输入到一个隐藏层的权重矩阵是词向量吗,根据博主的论述,隐藏层的输入时one-hot向量,然后词向量就是输入到隐藏层的权重矩阵,但是隐藏层的输入不应该是已经训练好的词向量吗,词向量不是在隐藏层之前映射得到的吗
我觉得词向量作为一个权重矩阵,以及作为一个映射 都是合理的解释,就看从什么角度看网络结构了。
请问word2vec的输出结果词向量,有直接的评价指标或方法吗,在不作为其他模型的输入的情况下。谢谢~~
可以参考一下我的博士论文,http://licstar.net/archives/687 里面有介绍一些词向量的评估方法。
请问楼主大神,初学者该怎么用最基础的python代码实现C&W模型呢?楼主有相关代码可以提供参考吗
C&W模型就是最朴素的前馈网络,图像方面有很多例子,可以参考着写。
博主您好。请问您在以下方面了解吗,用向量的方法可以进行句法分析吗。或者将句子转化成向量后可以提取出句法层面的信息吗,谢谢
句法分析有一些专门的模型,也有用上词向量的,但不是直接由词向量推导出句法结构。最近没关注这方面,你可以直接搜一下。
博主,您好,我是一名学生,刚开始做NLP方面的学习,看了您的博客以后很有感触,但是不知道从何开始学起,能不能给提些意见?谢谢!
您好,问一下,词向量e作为input的话,训练词向量的时候,E不是随机初始化的么,那不是相当于输入是随机的,然后里面参数也是未知的随机的,只有输出y已知,直观想的话,一个方程y=ax+b,除了y都不知道,那不是任意的组合都可以了,怎么求e和里面的参数呢