D 神用了一些碎片时间初步探索了一下 MMC,这个币全称是 Memory Coin,中文叫内存币,也是一个 CPU 币。内存币之所以只能用 CPU 挖,是因为它需要 1G 内存。计算前,它会先根据当前状态,创建一个 1G 内存的缓存,并且根据缓存里的数值,反复跳转几十次,最终挖到矿。如果用 GPU,给每个计算核心分配 1G 的显存几乎是不可想象的。当时主流的挖矿显卡,只有部分 A 卡的显存是上 G 的,但也只能调动起其中的一两个核心来挖矿,显卡的优势荡然无存。
经过一周的折腾,MMC 矿池总算走上了正轨,正当我们想歇一口气的时候,又一个杯具发生了。早上 7 点,金牌客服 X 突然在群里着急地说,矿池连不上了!
矿池在线算力为0
口碑不能砸,D 神赶紧到电脑前排查,一看,DigitalOcean 发了一封站内信,说我们的 IP 被人 DDoS 了,所以他们就把那个 IP 封了。申请解封之后不到 10 秒,系统又自动把这个 IP 封了。我们装了抓包软件,看看到底是什么样的攻击,又申请了一次解封,在那上线的几秒钟,我们看到了 1Gbits/s 的巨大流量(也不知道是不是网卡被打满了)。之后分析发现,是一种叫做 UDP DNS Query Flood 的攻击。虽然我们的服务器配置完全可以抵挡这样的攻击,但对于机房来说,这么大的流量会影响他的正常服务,就选择把我们关掉了。我们后来怎么申请,DigitalOcean 都不肯给我们解封了,只祝福我们“I hope you have better luck in the future”。
DDoS 当时用 nload 命令看到的效果
这个攻击者一看就是圈内人士,他只攻击了我们用来挖矿的 IP,而完全没去动我们 web 服务的 IP,一点资源都没有浪费。与此同时,mmcpool 也正在被攻击,只有那个 GPU 池还活着。把一个币交给一个黑池真是让人心痛啊。
其实这个 CPU 危机,就是上一章里挖的坑。矿池经过几天的发展,四核的机器也几乎已经满了,特别到了周末,挖矿的人也开始变多。必须要想办法优化了。
优化的过程充满了戏剧性,H 神抱着试一试地心理,搜了一下,发现 Go 语言可以调用 C 语言写的 so 模块。然后 H 神又抱着试一试的心理,试了一下两个 Go 和 C 版本 share 检查程序的速度,发现居然 C 比 Go 快 10 倍!于是这个问题就这么解决了,此时距离矿池上线刚刚一周……(要是一开始就知道可以 Go 调用 C 就好了,也免去了 H 神花了好几天把 C 的代码翻译成 Go 的,现在又要亲手把它废掉……)
那些年 Go 语言刚出来,宣传里面有提到说它是编译语言,性能非常好,堪比 C。大家听后都觉得顺理成章,都没想着怀疑一下,结果在我们这个计算密集的程序里,居然有 10 倍的性能差距。
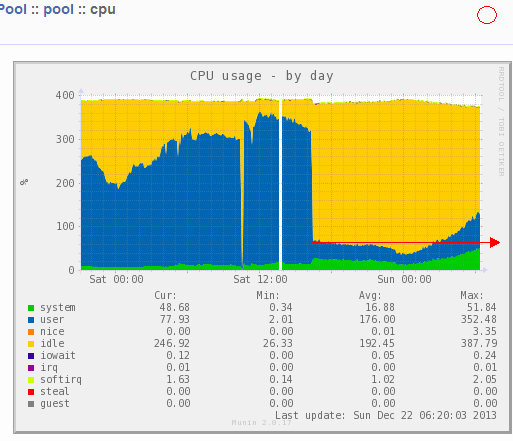
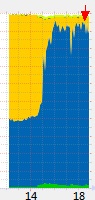
新版上线之后,CPU 使用率有了非常显著的降低,从此我们再也没担心过 CPU 的成本。有趣的是,就在我们更新新版之后的第二天,矿池的用户又开始猛增。要是没有 H 神的及时优化,CPU 占用应该已经到了红圈的位置了。
其实Go语言是自带内存回收机制的,当时的版本是 Go 1.2,传说这个版本的内存回收还不太成熟。我们自己体验到的就和传说中的一样。还有传说 Go 1.3 会改好 GC 问题(据R神介绍,实际上到了 1.5 版才算改好了),不过估计还得等大半年吧,可能等不到那一天矿池就倒闭了。那剩下的路子似乎只能是少申请内存:申请次数要少,能公用的内存就公用;申请的量也要少,这样至少可以减缓增速,多活几天。
优化的过程当然是非常的苦逼,自己挖的坑就得自己填,当初快糙猛写的代码,内存用的很随意,现在就一个个改吧。大多数还是非常好改的。除了直接改内存,我们还尽可能缩减“go”关键词的使用,每一次“go”都会有一些开销,积少成多。最早我们为了效率,把逻辑上可以并发的所有操作全都 go 了,经过这次精简,每个矿机只保留两个协程,一个等新块(与主程序通信),一个等 share(与矿机通信)。
虽说 DDoS 是分布式攻击,但是经过统计发现,这次攻击的 IP 比较集中,D 神、R 神、S 神经过讨论决定,先封杀连接数最多的 100 个
IP。当然,封杀 IP 这么高大上的功能,是不会存在于我们这么快糙猛做出来的矿池里了。好在 Linux 下,可以简单地配置 iptables 直接封杀来自某些 IP 的所有连接。就这样,经过 D 神的一番操作,矿工数降到了 7000。攻击者似乎也意识到了 D
神的封杀,放慢了攻击脚步。此时是下午 4 点,距离发现攻击刚过一小时。
矿池终于回到了正常状态,可以暂时歇一口气了。接下来的主要任务是优化程序的性能,避免成本一直上涨。但是在此之前,我们还是很想八卦一下这接近两万台机器,到底是谁的。可以肯定的是,这些机器挖到的矿都是给同一个钱包的,说明这些机器都是一个人的。但是谁会有这么多机器呢?我们想来想去觉得只有黑客手中的肉鸡,才会有这么大的规模。但是从 IP 分布来看,这些机器都集中在几个城市,网段也很接近,像是几个网吧的。不过网吧一般都有还原卡,不太容易中木马……真是越想越绕,不知道到底是何方神圣。还是随他去吧,能让我们赚钱就行。