晒代码发布前,我们构想了 N 种吸引人来发代码的策略。后讨论认定,如果网站发布初期就有大量的代码作为基础,之后则更有可能吸引人来晒代码。就像某百科和某社区问答建站初期那样。
本着这个目标,我试着用最简单粗暴的方法,尽可能多地从网上抽取出 ACM 代码。由于很多 ACMer 都会在网上开博客,博客里又很可能会写解题报告,有些解题报告会附上珍贵的 AC 代码。如果能把这里的 AC 代码都抽取出来,效果肯定会很理想。
下面就简单介绍一下整个代码抽取过程。
系统框架
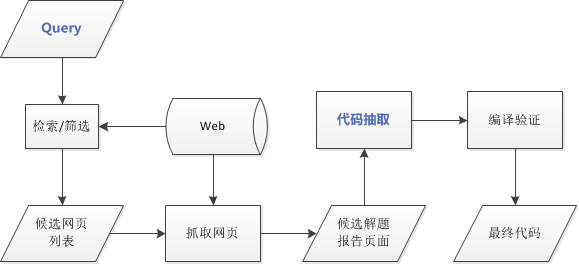
模块介绍
Query 生成及候选网页筛选
OJ名列表 = [“HDU”, “HDOJ”, “PKU”, “POJ”, “ZJU”, “ZOJ”, “SGU”, “Ural”];
Query 包括以下三种,“OJ名 include”、“OJ名 import”、“OJ名 题号”。题号穷举对应 OJ 实际有的题号。
对于前两种 Query,输入百度抓取所有的检索结果。对于第三种,每个 Query 只看前五页的结果。
抓取得到的所有网页列表去重后,还需要进一步地筛选。选取出网页标题里 OJ 名后紧跟(最多中间有一个字符)题号的那些网页,加入候选网页列表。
代码抽取器
通过抽样观察,可以发现,一般网页中的代码有两种形式出现:有明显边界的和无明显边界的。(废话一句)
先说说有明显边界的。大约有 1/4 的博客使用专门的代码插件来贴代码。代码插件主要有两个系列,分别是用<pre>标签和<textarea>标签装代码。处理这类网页时,只需要枚举网页 DOM 里面所有的<pre>标签和<textarea>标签。把里面的内容列入候选代码即可。
代码无明显边界的网页曾经困扰我很长时间,甚至一度想要采用大规模分布式人肉的方法来抽取代码了。正当一筹莫展之际,软件著作权申请时的两个必要条件令我茅塞顿开。这两个条件是:1. 代码要以“#include”开头;2. 代码要以“}”结尾。
网页中的 C/C++ 代码正好也可以用这种方法抽取出来。找到“#include”,然后使用括号匹配的算法(也就是跳过所有函数里面的大括号),遍历所有的“}”。所有得到的代码都加入候选。对于 Java 代码,除了将起点改为“import”之外,还需要把抽取结果中“public class”后面的类名改成“Main”。
其实第二种方法完全可以用于处理有明显边界的代码。这里保留了这两种方法,主要是考虑到有些代码的前面或后面会写一些有用的注释。
实验结果及评价
使用这种方法,一共在 48205 个候选网页中,有 11328 个网页通过有明显边界的方法抽取出了代码。在剩下的 36877 个网页中,又有 20777 个网页使用进一步的方法抽取出了代码。这里抽取出代码的标准是,抽取出可以编译通过的代码,并不是实际提交能 AC 的代码。抽取失败的那部分网页中,大多数的代码本身就不能编译通过,还有一部分是由于代码前面多了行号,要去除还得花点心思。
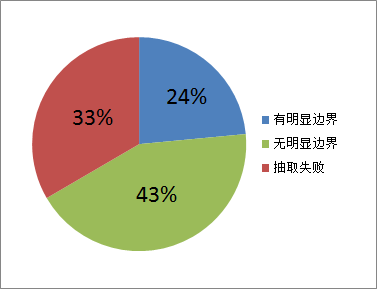
本文所述方法在各环节均有可改进之处。在候选网页筛选的过程中,强制限定网页标题中含有“OJ名 题号”是一个很严格的要求,必定会损失大量的解题报告。在代码抽取时,如果注释中含有大括号,就会导致抽取的错误。
从实践上看,总计不到一个工作日的编码时间,加上总共不到两天的挂机爬取和抽取时间,以及抽取得到的接近 50% 覆盖率的代码,本文描述的方法不失为一种可取的方法。
才子!
哈哈,厉害~
原来晒代码是这么来的~
这个真心强大